[Operating System] #6주차 - Storage Management
👻 Mass-Storage Structure
Secondary Storage같은 비휘발성 메모리를 의미한다. 주로 HDD 혹은 NVM(Non-Volatile Memory)이며 때때로 Magnetic Tapes(백업용으로 사용), Optical Disks, Cloud Storage 등이 있음! 해당 구조는 RAID 시스템을 사용한다.
- Hard Disk Drives(HDD)의 구조
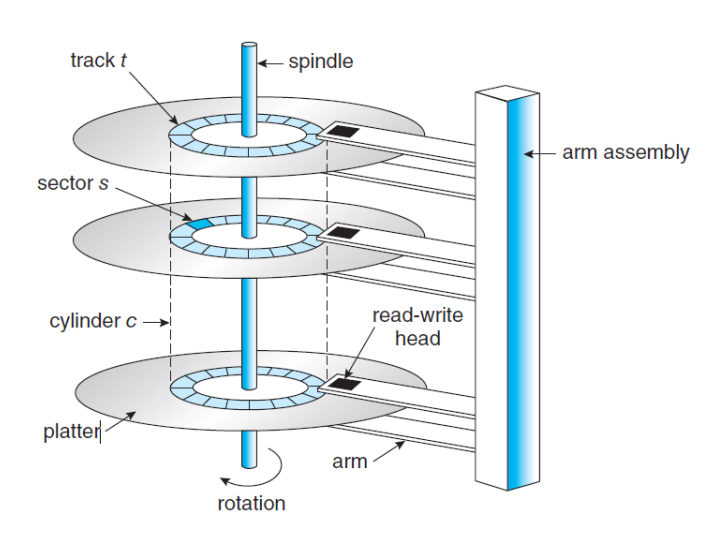
이러한 구조를 이용하려면 HDD Scheduling이 필요하다. 해당 스케줄링의 목표는 다음과 같다.
- 액세스 타임의 최소화(혹은 Seek Time)
- 데이터 전송의 Bandwidth(대역폭) 최대화
- Seek Time
- Device Arm이 Head를 움직이기 위해 Cylinder를 찾아가는 데 걸리는 시간
- Disk Bandwidth
- 데이터를 한 번에 전송할 수 있는 용량
HDD 스케줄링으로는 다음과 같은 방법들이 있다.
- FIFO Scheduling
- 아래 예시에서 Total Head Movement는 640 Cylinders
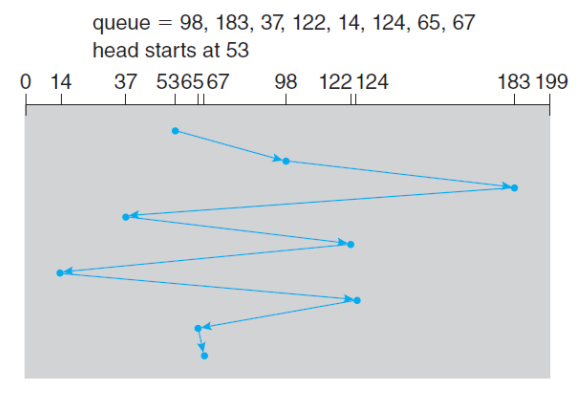
- 아래 예시에서 Total Head Movement는 640 Cylinders
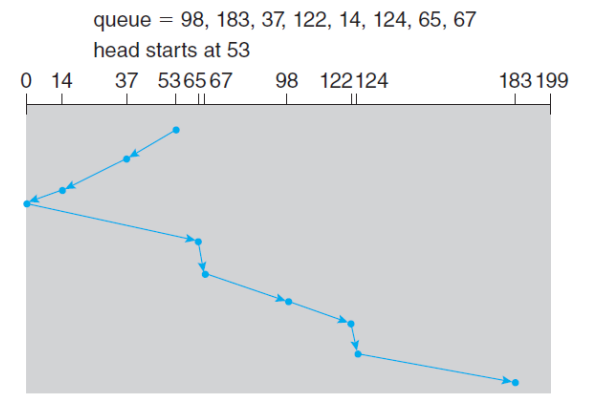
- SCAN Scheduling
- Dist Arm이 한 쪽 끝에서 시작해서 다른 쪽 끝으로 이동하는 방식
- 한 쪽 끝에 도달하면 방향을 바꿔 계속 진행한다.
- 아래 예시에서 Total Head Movement는 236 Cylinders
- C-SCAN(Circular-SCAN) Scheduling
- 한 방향으로만 헤드를 움직이는 방식
- 아래 예시에서 Total Head Movement는 183 Cylinders
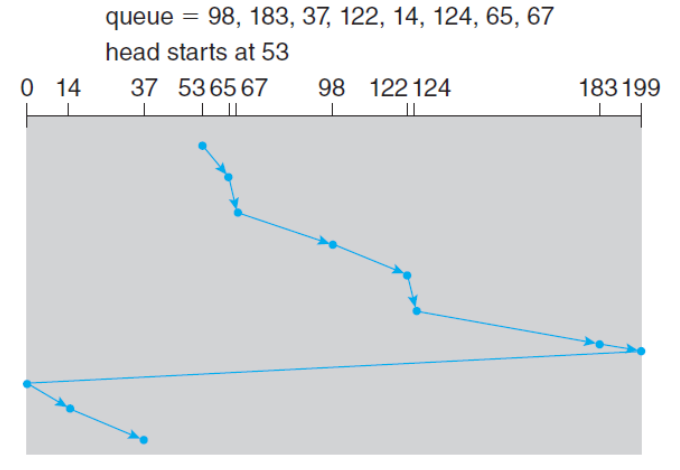
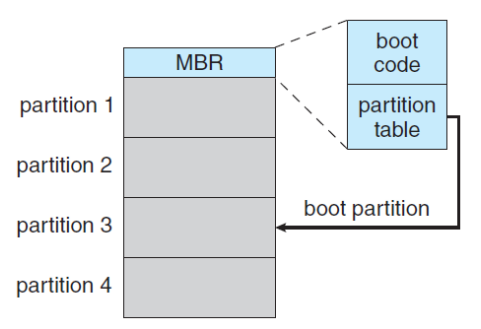
🌱 Boot Block
컴퓨터 부팅 시 가장 처음 실행된다. Bootstrap Loader가 NVM Flash Memory에 저장한 후 메모리를 매핑시켜준다. 이것도 Mass-Storage의 일종
🌱 RAID
Redundant Arrays of Independent Disks의 약자로, 데이터 전송 대역폭을 확대시키기 위해 사용된다. 장치가 병렬적으로 수행되면 데이터의 Read/Written의 비율을 향상시킬 수 있고, Redundant Information(중복된 정보)을 여러개의 장치에 저장 가능하기 때문에 스토리지의 신뢰도를 향상시킬 수 있다. 따라서 장치(드라이브)가 손상되어도 데이터를 잃을 가능성이 적어진다.
아래는 활용할 수 있는 RAID의 특성이다.
- Redundancy : Improvement of Reliability
- N개의 디스크에 데이터가 저장되어있는 것보다 Single 디스크일 때 데이터를 잃을 확률이 높다.
- Mean Time Between Failures(MTBF : 실패가 발생하는 평균 시간)를 제공한다.
- 신뢰도 문제의 해결 방법 : Redundancy
- 가장 간단한 방법 : Mirroring(Duplicate All The Drives)
- Parallelism : Improvement of Perfornamce
- 여러개의 장치를 이용해 데이터를 전송하면 전송률을 향상시킬 수 있다.
- Striping Data라고 함
- Bit-Level Striping
- 각 바이트의 비트로 Splitting
- Block-Level Striping
- Block 단위. 장치의 수를 일반화한 것
- 여러개의 장치를 이용해 데이터를 전송하면 전송률을 향상시킬 수 있다.
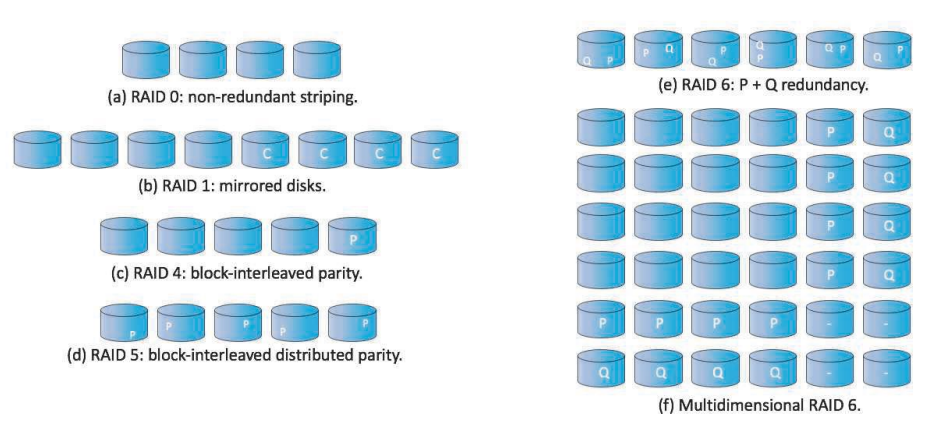
RAID는 레벨(Level)이라는 개념이 존재한다.
- Mirroring
- Highly Reliable
- Too Expensive
- Striping
- Highly Efficient
- Not Related to Reliability
- Parity Bit
- Set to 1 : 비트 수는 짝수(Even)
- Set to 0 : 비트 수는 홀수(Odd)
- 비트가 손상되었는지 확인할 수 있는 방법
- 에러를 감지하고 복구가 가능하다.
즉, RAID는 디스크의 레벨을 지정하여 비용과 성능 사이의 관계를 비교해 데이터의 Trade-Off를 수행한다.
Leave a comment