[Operating System] #5주차 - Virtual Memory
👻 Virtual Memory
가상 메모리(Virtual Memory)는 어떠한 프로세스의 실행을 메모리에 완전히 올리지 않아도 실행할 수 있도록 해주는 메모리이다. 그래서 프로그램이 물리적인 메모리보다 크더라도 실행 가능하게 해주며, 논리적 메모리와 물리적 메모리를 완전 분리가능하게 해주므로 파일 및 라이브러리 공유 혹은 프로세스 생성에 있어 효율적이다.
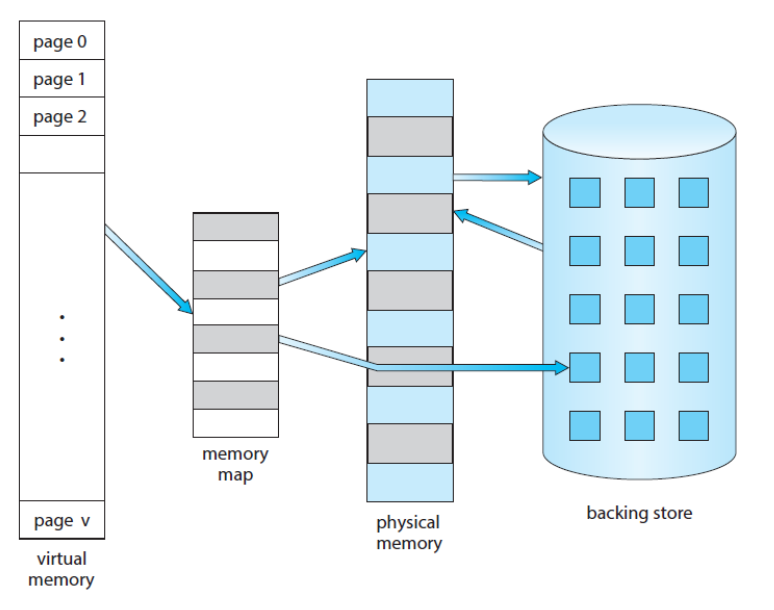
- Virtual Address Space
- 0번부터 시작 가능한 논리적 주소 공간
- 연속적인 메모리로 존재
가상 메모리를 사용하면 페이지 공유를 통해 파일과 메모리의 공유가 쉬워진다.
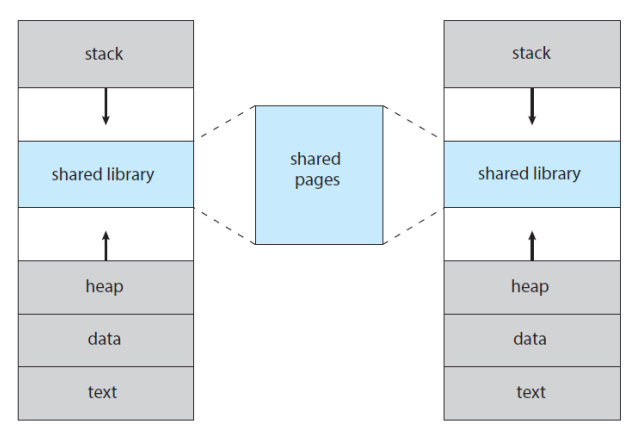
👻 Demand Paging
프로그램의 실행 과정이 어떻게 이루어지는지 고려해본다면,
- 제일 먼저 Secondary Storage(HDD, SSD)로부터 메모리로 로드하는 작업이 필요
- 한꺼번에 로딩할 필요는 없음
- 페이지 단위로 분할해서 올림
- 각각의 페이지를 언제 올릴까?
- Demand Paging : 요청할 때만 올리기
- Demand-Paged Virtual Memory의 관리는 어떻게하지?
Demand Paging의 기본적인 개념은 다음과 같다.
- 프로세스가 실행중일 땐, 해당 페이지가 메모리에 있다고 가정
- 어떤 경우에는 Secondary Storage에 있을 수도
- 어떠한 스토리지에 있는지 확인이 필요
- Valid-Invalid Bit 사용 가능
- valid : in memory
- invalid : in secondary storage
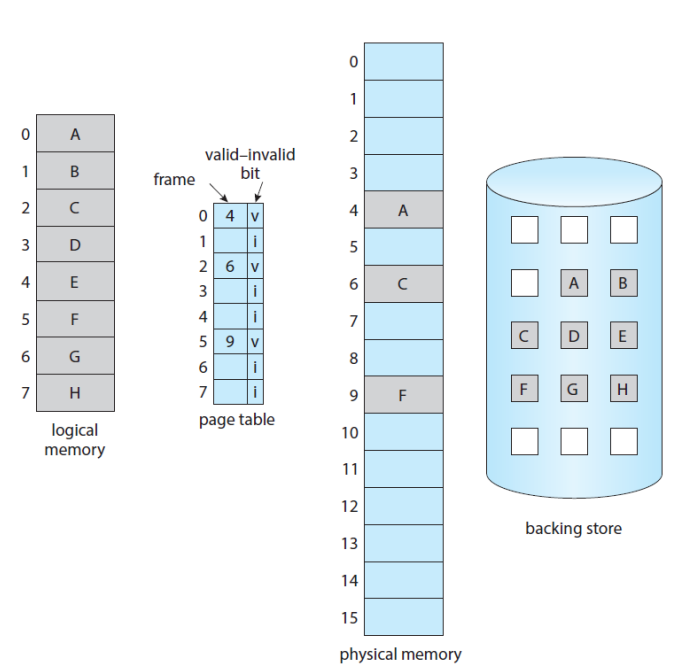
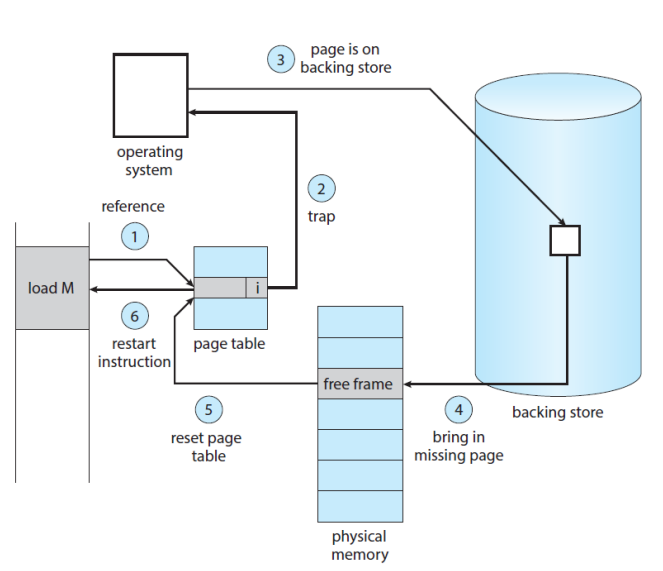
메모리에 로딩이 되지 않은 페이지에 액세스 했을 때, Page Fault가 발생한다. 이를 핸들링하는 방법은 아래와 같다.
- 내부 테이블 체크
- valid라면 프로세스 종료
- invalid라면 페이지를 메모리에 로드
- 그러려면 Free Frame을 찾아야 함 (free-frame list 사용)
- Secondary Storage에서 페이지를 읽어와 새 프레임에 로드
- 내부 테이블과 페이지 테이블을 valid로 수정
- 명령어 재실행
- Pure Demand Paging
- 페이지가 요구될 때까지 절대 가져오지 않음
- 메모리에 페이지가 없는 채로 프로세스 실행 시작
- 첫 번째 명령이 Page Fault를 일으키면 OS가 페이지를 로드
- 페이지가 필요할 때마다 로드해야하므로 좋지 않은 방법
- Locality of Reference(참조 국부성)
- 프로그램이 각각의 명령어를 실행할 때 항상 새로운 페이지를 액세스하지 않는 것
- 즉, 하나의 명령어에 여러개의 페이지를 로드해야할 때 페이지 개수만큼 Fault가 일어나진 않음
참조 국부성의 예시 코드로는 아래와 같다.
int i, j;
int[128][128] data;
// 명령어 실행마다 Page Fault 발생 가능성 다수
for (j = 0; j < 128; j++)
for (i = 0; i < 128; i++)
data[i][j] = 0;
// 명령어 실행 후 128번은 Page Fault 없이 실행
for (i = 0; i < 128; i++)
for (j = 0; j < 128l j++)
data[i][j] = 0;
2차원 배열은 연속적으로 메모리 할당이 되어있는 구조이다. 페이지의 크기가 128이라고 생각해본다면, 위의 이중 for문을 실행시켰을 때 매 실행마다 새로운 페이지를 불러와야한다. 하지만 아래의 이중 for문을 실행시킨다면 명령어를 한 번 실행시켰을 때 페이지 내에 존재하는 모든 데이터에 접근이 끝나야 새로운 페이지를 액세스하게 된다. 이러한 특성을 참조 국부성이라 한다.
💡 요즘 같이 뛰어난 성능을 가진 환경에서는 큰 차이가 없다.
- Hardware Support to Demand Paging
- Demand Paging을 위한 하드웨어적인 지원이 필요하다.
- Page Table
- Valid or Invalid를 저장하는 페이지 테이블 필요
- Secondary Memory: (=Swap Space)
- 현재 메모리에 위치하지 않는 페이지를 보관
💡 SSD는 Swap Paging이 빠르기 때문에 사용하면 좋다.
- Instruction Restart
- Page Fault가 일어났을 때 OS가 트랩을 걸게 되는데, 다시 시작할 때 같은 위치와 상태로 돌아가야한다.
- 마찬가지로 Instruction Fetch 과정에서 일어난다면, 해당 명령어를 재실행해야 한다.
- 연산(Fetching an Operand)도 마찬가지
- 나쁜 예
ADD A, B, C과정에서- ① Fetch and decode the instruction (ADD)
- ② Fetch A
- ③ Fetch B
- ④ ADD A and B
- ⑤ Store the sum in C
- Free Frame List
- OS가 Free Frame List를 관리해줘야 함
- Performance of Demand Paging
- Demand-Paged 메모리의 효과적인 액세스 타임을 어떻게 계산할까?
ma: memory-access timep: probability of a page fault- EAT = (1 - p) * ma + p * (page fault time)
ma<page fault time
- Page Fault 시 걸리는 시간?
- Service the page-fault interrupt
- Read in the page (대부분의 시간이 걸리는 작업)
- Restart the process
평균 Page-Fault 서비스 타임이 8ms. 메모리 액세스 타임이 200ns일 때,
EAT = (1 - p) * 200 + p * 8,000,000 = 200 + 7,999,800 * p만약, 1,000번 중 한 번의 Page Fault가 일어난다고 한다면, (p = 0.001)
EAT = 200 + 7999.8 = 8199.8ns ≒ 8.2ms
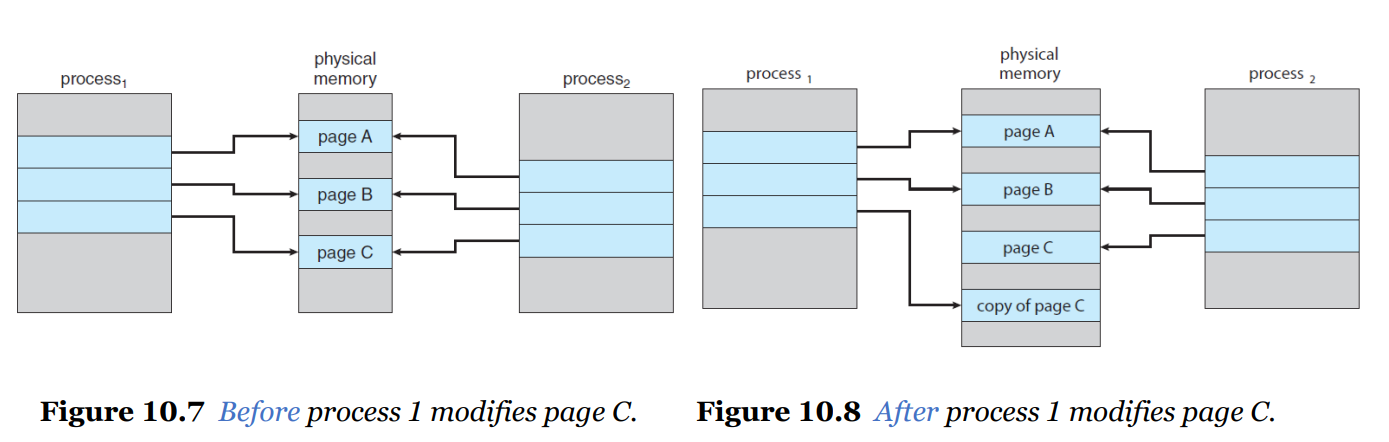
👻 Copy-on-Write
쓰기를 할 때 복사를 하자. 즉, Shared Page를 프로세스가 Write 할 때 해당 공유 페이지를 Copy하는 것.
🐓 Page Replacement
만약 Free Frames가 없다면 Page In-Out은 어떻게 해야할까?
멀티프로그래밍의 정도를 늘리게되면 모든 물리적 메모리 공간을 사용하게 될 것이다. 페이지가 모든 공간을 차지한 경우 Swapping을 할 수 없게 되는데, 이러한 상태에서 페이지를 교체할 수 있는 알고리즘에 대해 알아보자.
- Page Fault Service Routine incl. Page Replacement
- ① Secondary Storage에서 요구된 페이지 찾기
- ② Free Frame 찾기
- Free Frame이 있으면 해당 프레임 사용
- 없다면, PR 알고리즘을 이용해 Victim Frame 선택
- Victim Frame을 Secondary Strogae에 쓰고, 페이지 교체
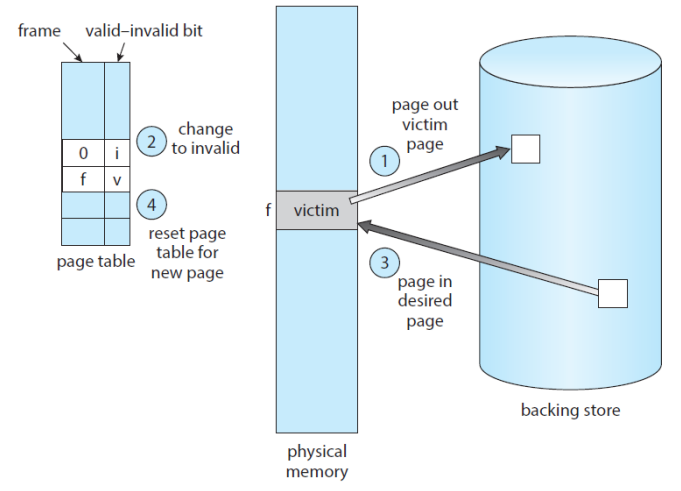
PR(Page Replacement) 알고리즘을 적용하는 과정에서 발생하는 큰 두 가지 문제점이 있다.
- Frame-Allocation Algorithm
- 각 프로세스에 몇 개의 프레임을 할당해야 효율적인지?
- Page-Replacement Algorithm
- 교체하려는 프레임을 어떻게 선택해야할지?
Secondary Storage I/O는 굉장히 비싸기 때문에 이 부분의 성능을 조금만 향상시켜도 많이 개선될 것이다.
해당 부분을 개선시키려면 Page Fault를 줄이는 것이 가장 단순한 방법이다.
- Evaluation of Page Replacement Algorithms
- Reference String(참조 문자열)
- 참조 메모리를 페이지 번호 순으로 나열한 것
- Reference String을 이용해 Page Fault를 카운트할 수 있다.
- Page Frame의 개수? 시스템마다 다름
- The more Frames, the less page faults
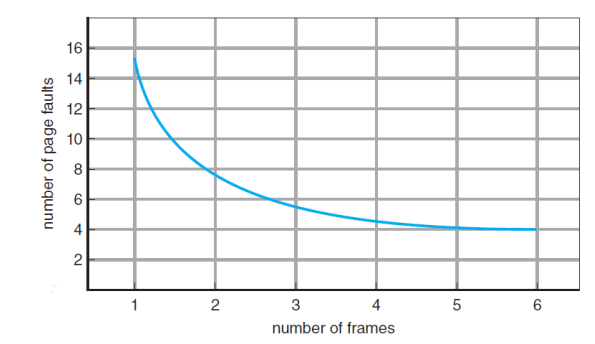
- The more Frames, the less page faults
- Reference String(참조 문자열)
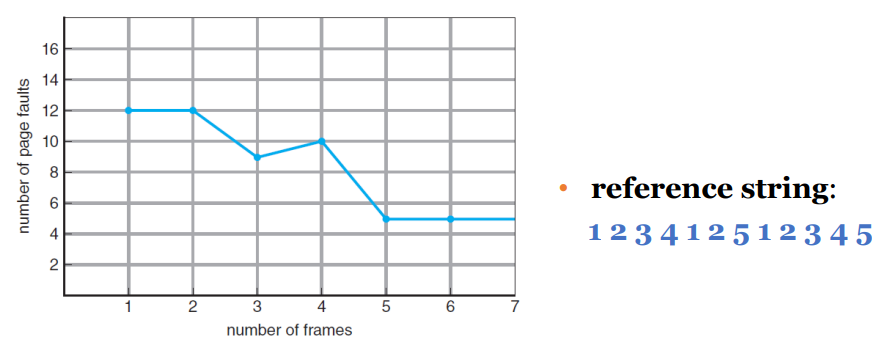
🌱 FIFO PR
오래된 페이지를 Victim으로 선택하여 교체하는 가장 단순한 방법이다.
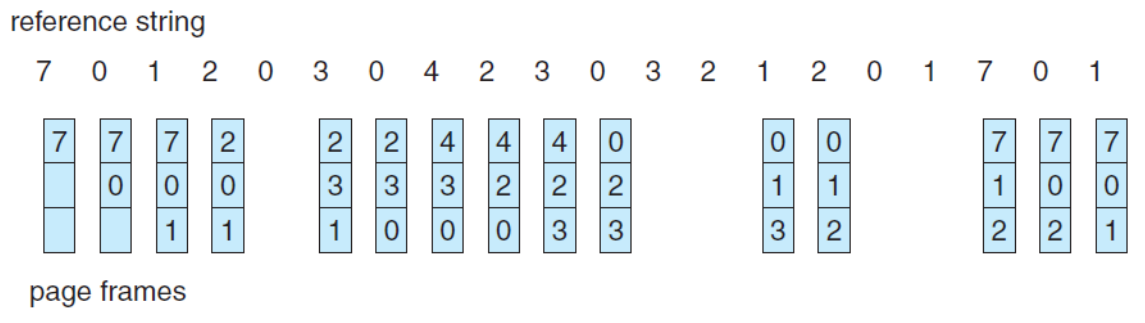
위의 예시에서는 15번의 Page Faults가 발생했다.
- Belady’s Anomaly
- FIFO PR Algorithm 사용 시 발생하는 가장 큰 문제
- 프레임 할당 수가 늘어날수록 Page Fault Rate가 증가되는 현상
🌱 Optimal PR
이러한 현상을 방지하는 최선의 선택은 무엇일까?
최적의 PR 알고리즘인 OPT Algorithm은 앞으로 사용하지 않을 것 같은 페이지를 Victim으로 선택해 교체하는 방법이다.
OPT 혹은 MIN이라고도 부르며 해당 알고리즘으로 가장 낮은 Page Fault Rate를 보장할 수 있다.
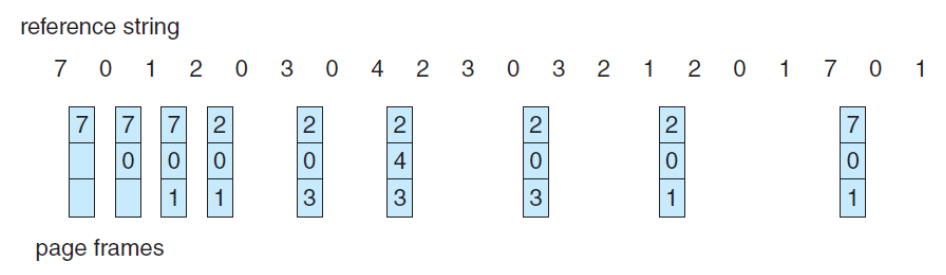
위의 예시에서는 9번의 Page Faults가 발생했다. FIFO 알고리즘과 비교해보면 훨씬 효율적인 것을 알 수 있다.
해당 알고리즘의 문제점은 CPU 스케줄링에서의 SJF 알고리즘과 비슷하게 Future Knowledge가 필요하다는 점이다. 따라서 구현이 불가능하며 다른 알고리즘과 비교하여 얼마나 효율적인지 판단만 가능하다.
마찬가지로 최근 과거를 이용해 가까운 미래를 예측하는 것도 가능하다. 이러한 점을 이용하면 과거의 정보들로부터 가장 최근에 사용하지 않은 페이지를 유추할 수 있다. 이러한 생각에서 나온 알고리즘이 LRU Algorithm이다.
🌱 LRU PR
LRU(Least Recently Used)는 가장 최근에 사용하지 않은 페이지를 Victim으로 선택해 교체하는 방법이다.
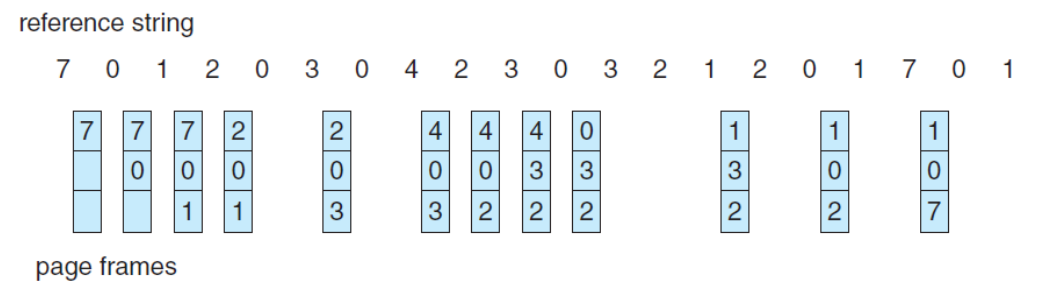
위의 예시에서는 12번의 Page Raults가 발생했다.
- LRU Policy
- 성능도 좋고 자주 사용된다.
- 실제로 구현하기 위해선 해당 프레임이 언제 마지막으로 사용되었는 지를 알아야한다.
- 위의 방법은 구현하기 복잡해서 하드웨어적 지원을 받으면 좋다. (이것도 쉽지는 않음)
counter와stack을 이용하면 가능
- OPT와 마찬가지로 Belady’s Anomaly를 겪지 않는다.
- Two Implementation Methods for the LRU
- Counter implementation
- 페이지를 참조할 때마다 카운터(혹은 clock)를 복사한다.
- 가장 적은 값을 가진 페이지를 교체
- Stack implementation
- Page Numbers를 스택에 저장
- 가장 최근에 사용된 페이지 넘버를 스택 최상단으로 교체
- 프레임이 모두 찼을 경우, 스택의 Bottom이 Victim Page가 됨
- Counter implementation
- LRU-Approximation
- 해당 알고리즘은 하드웨어적 지원이 필요
- 하지만 많은 시스템은 Reference Bit만 제공
- Reference Bit
- 0으로 초기화, 페이지 참조시마다 1로 세팅
- 교체되면 다시 0으로 세팅
- Second-Chance Algorithm
- FIFO 알고리즘 사용
- 만약에 Reference Bit가 0이면 교체
- 1이면 0으로 변경하고 기회를 한 번 더 줌
- 한 번 더 걸리면 Victim으로 지정하고 교체
- 즉, LRU-Approximation(근사) 알고리즘
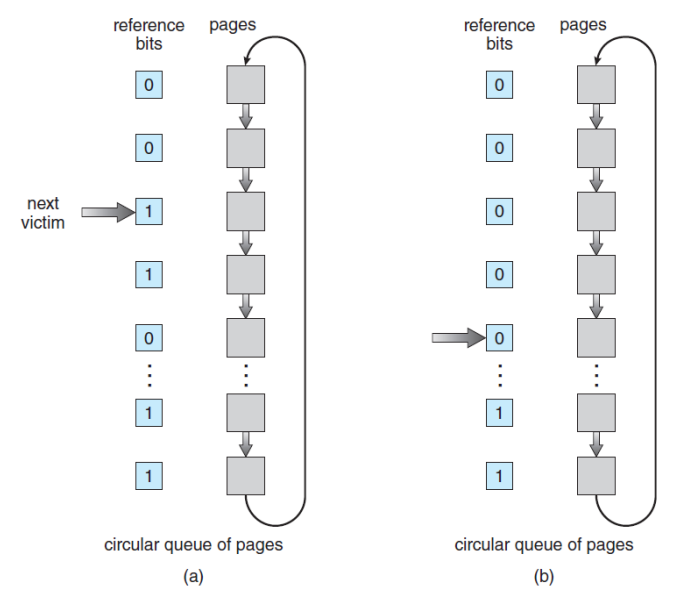
- 해당 알고리즘은 하드웨어적 지원이 필요
👻 Allocation of Frames
PR 작업을 수행할 땐, 프레임 할당 과정에서도 고려해봐야 한다.
예를 들어 128프레임을 가지는 시스템이 있고, OS가 35프레임, 유저 프로세스가 93프레임을 가지고 있다고 가정해보자. 그리고 두 개의 프로세스가 각각 93개의 프레임을 할당받고 싶어 요청을 하게 된다면, 각각의 프로세스에 얼마나 많은 프레임을 할당시켜야 효율적일까?
위와 같은 상황에서 프레임을 할당하는 방법엔 크게 두 가지 비교군이 있다.
- Equal vs Proportional
- Equal Allocation
- 모든 프로세스에게 동일하게 공유해주는 것
- Proportional Allocation
- 많은 프레임을 필요로 하는 프로세스에게 더 많은 사이즈를 주는 것
- Equal Allocation
다음은 Victim Page를 선택하는 기준이다.
- Global vs Local
- Global Replacement
- 시스템의 모든 프레임 중에서 Victim을 선택
- Local Replacement
- 자기 자신이 할당한 프레임에서 Victim을 선택
- Global Replacement
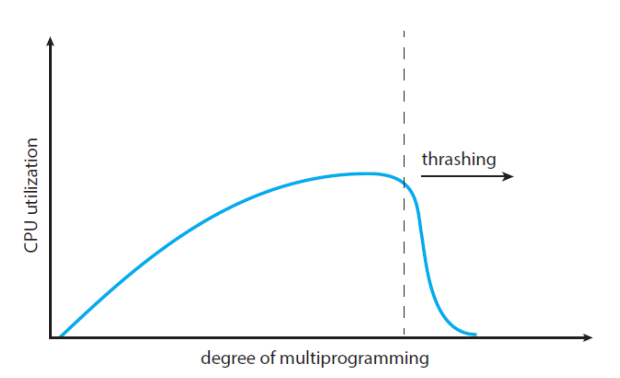
👻 Thrashing
가상 메모리를 사용하면 하드웨어와 무관하게 큰 시스템을 사용할 수도 있지만 어떤 프로세스가 Page를 In-Out하는 과정이 너무 바쁜 경우(Busy Swapping)가 생길 수도 있다.
이러한 경우는 프로세스가 충분한 페이지를 가지고 있지 않으면 발생하며 Page Fault Rate가 높아진다. 즉 멀티프로그래밍의 정도가 높아질수록 Page Fault Rate가 높아지는 것이다.
그렇게 되면 CPU 점유율도 높아지게 되는데, 어느 순간 점유율이 급격히 낮아지는 현상이 발생한다. 이를 Thrashing이라고 한다.
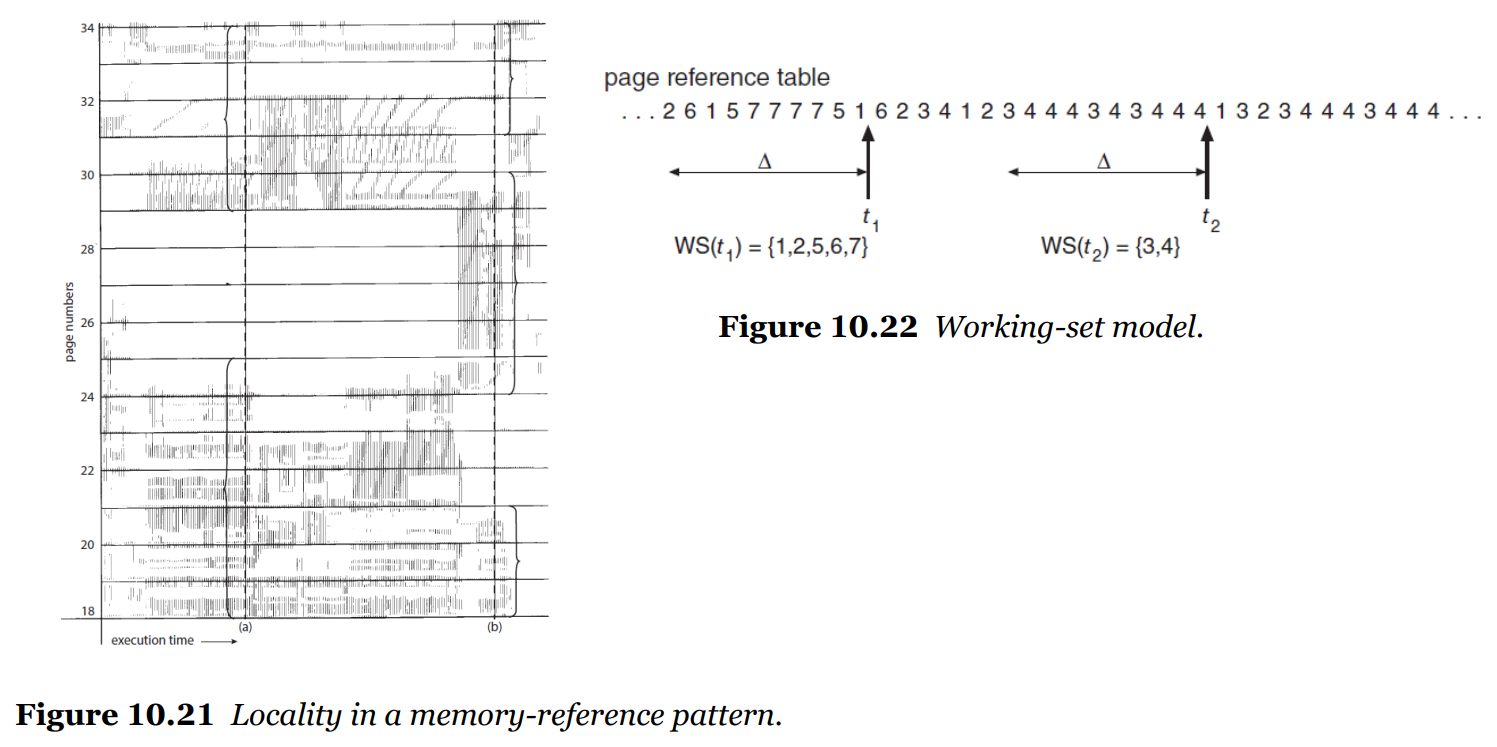
🌱 Working-Set Model
스레싱 현상을 해결하기 위한 모델.
- 참조 국부성을 기본적인 개념으로 생각(이용)
- parameter Δ(델타) 크기 만큼 Working-Set Window 지정
- Working-Set
- 해당 집합에 있는 페이지가 가장 최근에 참조된 페이지들
- 만약 페이지가 Active Use 상태라면 Working Set 내부에 있음
- 오랫동안 사용되지 않으면 Working Set 외부에 있음
- 프로세스에 할당된 페이지 크기보다 Working Set이 더 크면 Thrashing 발생
👻 글을 마치며
이번 시간에는 가상 메모리와 이를 이용한 Demand Paging에 대해 알아보았다. 흠.. 솔직히 이해를 100% 하진 못 한 것 같다 ㅠㅠ 그래도 최대한 흐름을 이해해보려 강의를 듣다 이해가 가지 않는 부분을 구글링하는데 조금씩 개념이 잡히는 건 느껴진다.. 아직 나는 멀었나봐.. 페이지 부분부터 복습을 해야할 것 같다. 완벽히 이해하는 그 날까지.. 포기하지만 말자!
Leave a comment