[Operating System] #4주차 - Deadlocks
👻 Deadlock
데드락(Deadlock)이란 프로세스의 집합 내의 한 프로세스에 한해 다른 프로세스가 인터럽트를 걸어주길 바라는 상황(wait() 상태)에서 해당 이벤트를 웨이팅하면서 멈추는 교착 상태를 의미한다.
- 데드락의 상황
- waiting thread가 다시는 자신의 상태를 바꾸지 못함
- 스레드가 요청한 리소스가 다른 스레드에 의해 점유되어 있을 때
한정된 자원이 여러 개의 동기화 되어야 할 스레드들에 의해 공유되고 있을 때, 리소스를 여러 개의 타입으로 구분할 수 있다.
👉 CPU cycles, files, I/O devices(such as printers, drives, etc.)
이러한 리소스 타입의 인스턴스가 중요하지 리소스 개수는 중요하지 않다.
스레드는 다음과 같은 과정으로 리소스를 활용한다.
Request - Use - Release
- 데드락 예시
pthread_mutex_t first_mutex;
pthread_mutex_t second_mutex;
pthread_mutex_init(&first_mutex, NULL);
pthread_mutex_init(&second_mutex, NULL);
/* thread_one runs in this function */
void *do_work_one(void *param)
{
pthread_mutex_lock(&first_mutex);
pthread_mutex_lock(&second_mutex);
/*
* Do some work
*/
pthread_mutex_unlock(&second_mutex);
pthread_mutex_unlock(&first_mutex);
pthread_exit(0);
}
/* thread_two runs in this function */
void *do_work_two(void *param)
{
pthread_mutex_lock(&second_mutex);
pthread_mutex_lock(&first_mutex);
/*
* Do some work
*/
pthread_mutex_unlock(&first_mutex);
pthread_mutex_unlock(&second_mutex);
pthread_exit(0);
}
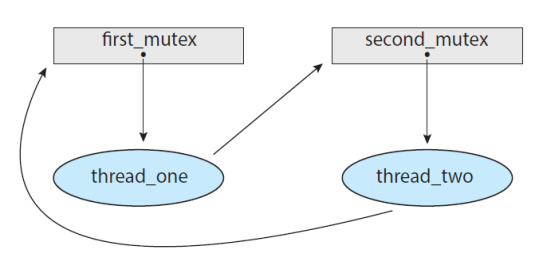
위와 같은 상황은 데드락이 걸리기 쉬운 환경이다.
thread_one에서 second_mutex에게 lock을 주려할 때 thread_two가 second_mutex에게 lock을 주면 데드락에 걸리게 된다.
🌱 Deadlock Characterization
데드락은 다음의 네 가지 조건을 모두 성립하면 발생한다.
- Mutual Exclusion
- 적어도 하나의 리소스가 공유하지 않는 상태
- 모두 읽기만 하는 리소스(Sharable)면 발생하지 않음
- Hold and Wait
- 점유 및 대기를 해야함
- 어떠한 스레드가 적어도 하나의 리소스를 점유하고 Acquire를 대기해야 발생
- No Preemption(선점 불가)
- 리소스가 선점될 수 없을 때 (뺏을 수 없을 때)
- Circular Wait
- 순환 대기
- 두 개의 스레드를 예시로 들면 돌아가면서 서로의 상태 대기를 하는 상황
위 조건을 모두 만족해야하기 때문에 데드락은 잘 발생하지 않는다.. 근데 발생하면 죽음😵
- Resource-Allocation Graph
- 데드락을 쉽게 이해하기 위해 만든 그래프
- 정점 집합 V와 간선 집합 E으로 이루어진 그래프
- 두 가지 타입이 존재
- 스레드 집합 T = { T1, T2, …, Tn }
- 리소스 집합 R = { R1, R2, …, Tm }
- Directed Edge : Ti 👉 Rj
- 스레드 Ti가 리소스 Rj를 요구
- Directed Edge : Rj 👉 Ti
- 리소스 Rj가 스레드 Ti에 할당
- 위의 두 간선은 타입이 다르다.
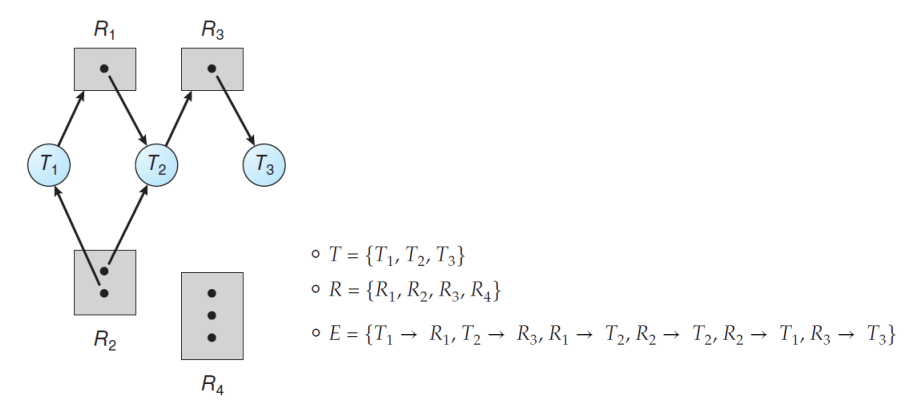
▲ Deadlock 안 걸림
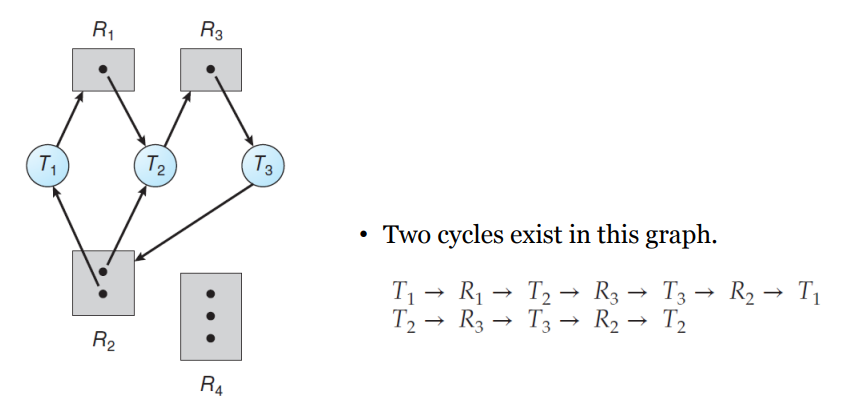
▲ Deadlock 걸림
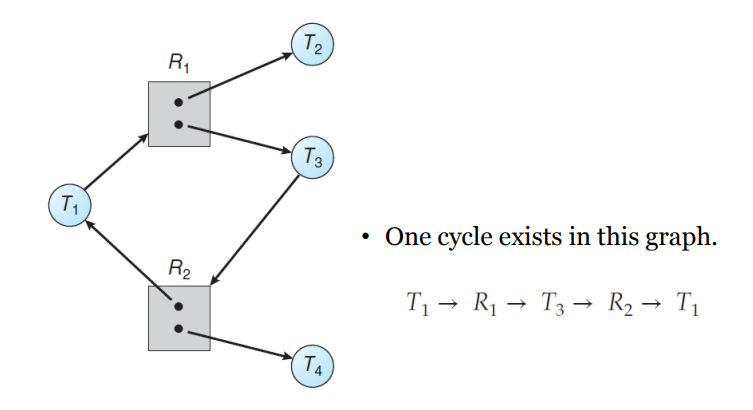
▲ Deadlock 걸릴 것 같지만 안 걸림
즉, 사이클이 없으면 데드락에 걸릴 위험이 절대 없다. 하지만 사이클이 있으면 데드락 상황이 발생할 수도 있지만 발생하지 않을 수도 있다.
👻 데드락을 핸들링하는 방법
데드락 문제를 핸들링하는 세 가지 방법이 있다.
- Ignore the problem altogether
- 데드락이 일어나지 않을 것처럼 무시..(이게 방법?)
- Use a protocol to prevent or avoid deadlocks
- 절대 일어나지 않도록 방지, 피하기
- 하지만 이 방법은 절대 불가능함
- 아주 비싼 시스템에나 적용하지 일반적인 시스템엔 부담스러움
- Deadlock Prevention
- Banker’s Algorithm
- Deadlock Avoidance
- 데드락이 발생했을 때 처리하기
- Detect and Recover
- Deadlock Detection
- Recovery from Deadlock
🌱 Deadlock Prevention
네 개의 발생 조건 중 하나만 막으면 되지 않을까?
- Mutual Exclusion
- 모든 리소스를 공유 가능하도록 만든다면?
- 적용 불가 (Mutex lock을 공유? 절대 있을 수 없는 일)
- 불가능
- 모든 리소스를 공유 가능하도록 만든다면?
- Hold and Wait
- 어떤 스레드가 리소스를 점유하고 있을 때 다른 리소스를 hold하고 있지 않는다면?
- 쉽지만 Impractical(비실용적)이다.
- No Preemption
- 리소스를 선점할 수 있도록 한다면?
- 리소스를 빼앗긴 스레드는 많은 문제가 발생할 수 있다.
- 선점된 리소스는 다시 리소스 리스트에 들어가고 다른 대기중인 스레드가 사용할 수 있기 때문
- Hold and Wait 방식과 스스로 내려놓느냐, 뺏기느냐의 차이일 뿐 마찬가지로 비실용적이다.
- Circular Wait
- 리소스 타입에 순서를 부여하자!
- 리소스를 요청할 때 현재 점유하고 있는 리소스보다 오름차순으로 요청
- 데드락 방지는 되겠지만 Starvation 발생이 높아짐
- 증명 가능함
- 하지만 lock ordering도 Deadlock Prevention을 보장할 수는 없다.
💡 Deadlock example with lock ordering
다음은 계좌이체 트랜잭션을 예시로 든 코드이다.void transaction(Account from, Account to, double amount) { mutex lock1, lock2; lock1 = get_lock(from); lock2 = get_lock(to); acquire(lock1); acquire(lock2); withdraw(from, amount); deposit(to, amount); release(lock2); release(lock1); }아래의 호출이 동시에 수행되면 데드락이 발생된다.
transaction(checking_account, savings_account, 25.0); transaction(savings_account, checking_account, 50.0);
🌱 Deadlock Avoidance
데드락을 예방하지 못하면 아예 피해버리는 방법
어떠한 요청이 왔을 때, 이 요청을 받아주기 전에 잠시 Future Deadlock을 고려해보는 방법이다. (그 동안 스레드는 대기 상태)
이 방법을 적용하려면 어떤 식으로 요청 과정이 이루어지는지 알아야 한다.
💡 예를 들어 스레드 P가 리소스 R1을 점유하고 있는 상태에서 R2를 요청하고, 동시에 스레드 Q가 반대 상황일 때
👉 각각의 요청 상황에서 Future Deadlock을 고려해보는 것.
선행 지식을 이용하여 어떠한 알고리즘으로 Deadlock State에 들어가는 것을 막을 수 있다는 것이 Deadlock Avoidance의 기본 아이디어이다. 이러한 선행 지식으로는 스레드가 요구할 수 있는 최대 리소스 개수와 요청 가능한, 그리고 할당받은 리소스의 개수가 있다.
- Safe State
- Deadlock Free
- 어떠한 리소스를 맥시멈까지 할당해줄 수 있는 상태
- 스레드의 실행 순서가 존재함
- 어떤 시스템이 Safe State란 것은 Safe Sequence가 존재한다는 것
- 즉, 이러한 Safe Sequence를 찾아내는 것이 메인
- Unsafe State
- Deadlocked State를 포함하는 상태
- Deadlocked State
- 데드락 상태
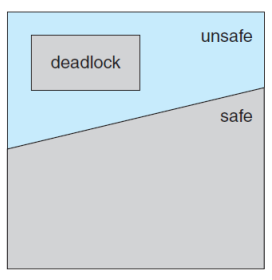
아예 Safe State에만 머무르도록 하면 데드락을 피할 수 있겠다!
시스템 초기 상태는 Safe State이다. 그 후, 리소스를 요청할 때마다 항상 확인하고 리소스를 할당해줄지 말지 결정한다. 요청 이후에도 Safe State에 머무른다면 요청을 승인해주고, 아니면 거절(Reject)한다.
RAG(Resource-Allocation Graph)를 한 번 더 생각해보자. 이는 인스턴스가 하나일 경우에는 부드럽게 작동한다. 스레드가 요청하는 작업을 나타내는 Claim Edge를 추가해서 사이클이 생기는지 아닌지 확인할 수 있다.
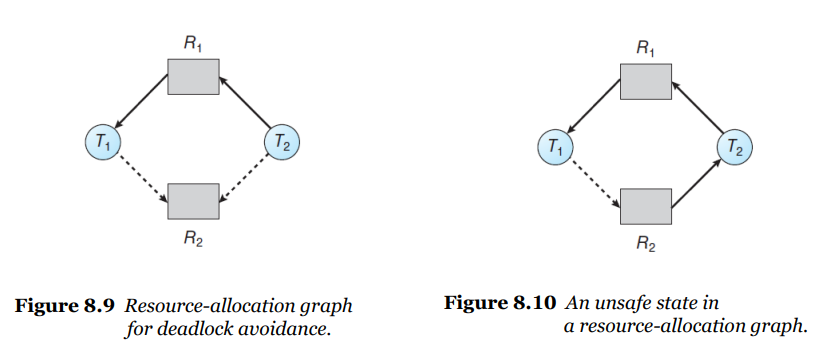
▲ 점선으로 표시된 Edge는 Claim Edge를 의미한다.
하지만 RAG는 인스턴스 개수에 따라 결과가 달라지기 때문에 여러 개의 인스턴스를 가진 각각의 리소스에 대해선 해당되지 않는다.
- Banker’s Algorithm
- RAG보다 훨씬 효율적이고 무겁고 복잡함
- 은행은 절대 내 돈을 아무에게 주지 않기 때문에 bank라는 이름이 붙음
- 데이터 구조
- n개의 스레드와 m개의 리소스 타입
- Available : 사용 가능한 리소스 타입의 개수 (
Vector) - Max : 스레드가 요구할 수 있는 최대 리소스 인스턴스의 개수 (
Matrix) - Allocation : 각 스레드가 현재 할당받은 리소스의 개수 (
Matrix) - Need : 앞으로 요청할 리소스 (
Matrix)
- Safety Algorithm

- Resource-Request Algorithm

🌱 Deadlock Detection
Deadlock Avoidance는 좋은 방법이지만 리소스를 요청할 때마다 실행되어야 하기 때문에 부담스럽다. 그래서, 조금 더 가볍게 데드락 상태는 허용해주되 감시하는 방법이 Deadlock Detection이다.
마찬가지로 싱글 인스턴스일 경우 Wait-for Graph를 유지한다. 주기적으로 알고리즘을 이용해 사이클 발생 여부를 확인한다.
💡 Wait-for Graph
👉 RAG에서 자원(리소스)만 뺀 그래프
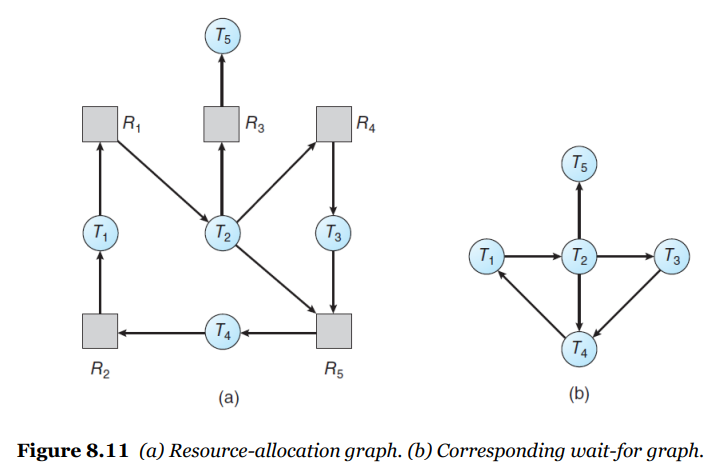
여러개의 인스턴스일 경우 뱅커 알고리즘과 유사한 방식을 수행한다. 데이터 구조로 Available과 Allocation은 동일하고 Request를 추가로 사용한다.
💡 Request : 현재 각 스레드의 요청
- Detection Algorithm

👻 Recovery from Deadlock
Detection Algorithm을 언제 실행할까?
- 얼마나 자주 데드락이 일어나는지?
- 당연히 데드락이 자주 발생할 경우 더 많은 Detection이 실행될 것이다.
- 스레드가 얼마나 많이 관여할건지?
- 스레드가 많을수록 사이클 발생 가능성도 더 커진다.
- Invoking for every request vs Invoking at defined intervals
- 요청마다 실행할건지, 주기적으로 실행할건지
- Detection Algorithm을 실행하는 주기가 길다면 많은 사이클이 발생할 수 있다.
데드락이 발견 되면 해야하는 것
- Inform the Operator
- 재부팅
- Recover
- Process and Thread Termination
- 데드락 걸린 프로세스를 포함한 집합 내 모든 프로세스를 죽이기
- 데드락 사이클이 풀릴 때까지 프로세스 하나씩 죽이기
- Resource Preemption
- Selecting a Victim : 최소 비용으로 손해볼 수 있는 프로세스 선택
- Rollback : 프로세스 Restart
- Starvation : 희생자로 선택되는 프로세스가 Starvation 걸리지 않도록 유한한 횟수 지정
- Process and Thread Termination
👻 글을 마치며
이번 시간에는 데드락에 대해 알아보았다. 유일하게 지금까지 기억이 났던 단어!! 근데 가장 어려운 파트라고 해서 집중해서 들었던 것 같다. 교수님 근데 너무 헷갈려요 ㅠㅠ 생각보다 데드락 걸리는 조건이 까다롭다는 걸 알게 되었고 그를 해결하는 다양한 알고리즘이 있다는 것이 신기했다. 모든 건 가장 간단한 생각에서부터 나온다는..
Leave a comment