[Operating System] #3주차 - Synchronization Tools (1)
👻 복습
- 프로세스 간의 통신(Share Data) 방법
- Shared Memory
- Message Passing
- 스레드 간의 통신 방법
- 이미 Data를 공유하고 있음
이렇게 서로 간 데이터를 공유하는 과정에서 Data Inconsistency(데이터 불일치)를 주의해야 한다. 이는 데이터를 주고받을 때 발생한다. 또한 Concurrently 할 때 문제가 발생하지 않을 것 같지만 이러한 상황에서도 발생한다.
count++, count--를 예로 들면, 이는 기계어에서 3단계의 연산으로 이뤄지는데 중간에 Context Switch가 일어나면서 계산이 꼬일 수 있게 된다.
// count++
register1 = count
register1 = register1 + 1
count = register1
// count--
register2 = count
register2 = register2 - 1
count = register2
Concurrent하게 실행된다면 count++와 count--는 다음과 같이 수행될 것이다.

👻 Race Condition
두 개 이상의 프로세스 혹은 스레드가 데이터를 공유하고 있을 때, Concurrently하게 처리하려 하면 실행의 결과는 어떠한 순서로 처리되느냐에 따라 달라진다. 이를 Race Condition(경쟁 상태)라고 한다.
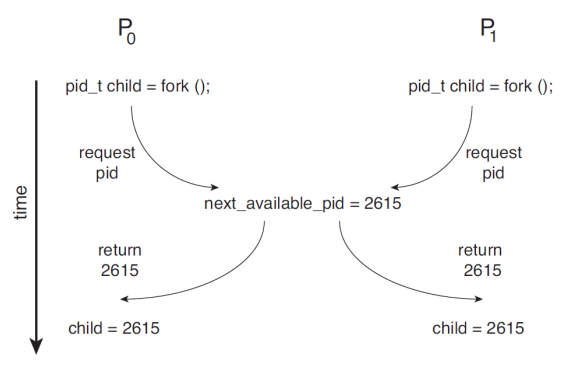
- 해결 방법
- 특정 시간에 오로지 하나의 프로세스만 계산할 수 있도록 한다.
이를 Process(or Thread) Synchronization(동기화)라고 한다.
👻 The Critical Section Problem
The Critical Section Problem를 직역하면 임계 영역 문제이다.
다른 프로세스와 공유하는 공간을 크리티컬 영역(Critical Section)이라고 하며 이 부분을 두개 이상의 프로세스가 공유하면 발생하는 문제이다.
- 해결 방법
- 여기(크리티컬 영역)에 진입할 수 없게 한다면 Race Condition이 해결될 수 있지 않을까?
- 하나의 프로세스가 크리티컬 영역을 실행중일 때, 다른 프로세스들이 해당 영역을 동시간에 실행하지 않도록 한다.
- 어떻게?
- 코드의 Section(영역)을 나눈다.
- entry-section : 크리티컬 영역에 진입하겠다 알려줌
- critical-section : 여기에서는 Context Switching이 발생하지 않는다.
- exit-section : 크리티컬 영역에서 나왔다 알려줌
- remainder-section : 나머지 영역
- 코드의 Section(영역)을 나눈다.
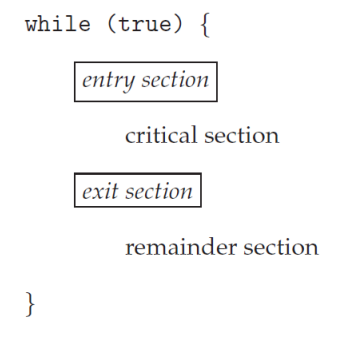
이 문제를 해결하기 위한 세 가지의 목표는 다음과 같다.
- Mutual Exclusion
- 상호 배제를 반드시 보장해줘야한다.
- 이걸 지킨다면 두 가지 문제가 발생할 수 있다.
- Deadlock
- Starvation
- Progress(avoid Deadlock)
- 무한대로 진입 연기되는 상황을 막자.
- 크리티컬 영역에 프로세스가 없고, 들어가고자하는 프로세스가 있다면 다음으로 들어갈 프로세스를 선택하는 것
- Bounded Waiting(avoid Starvation)
- 한정된 대기
- 기다리는 시간의 한계치를 정해주어 무한 대기 상태가 되지 않도록 해주는 것
해당 문제를 모두 해결하는 방법은 굉장히 어렵기 때문에 현실에선 쓰지 않는다.
다만, Single-Core 환경의 경우, 아예 인터럽트를 발생하지 못하게 막아서 간단하게 해결할 수 있다. 하지만 이는 너무 간단한 방법이므로 멀티프로세스와 같이 조금만 복잡해져도 사용할 수 없다.
이를 해결하기 위해 두 가지의 대중적인 접근 방법이 있다.
- Non-Preemptive Kernel
- 커널 모드 프로세스가 커널 모드를 빠져나오거나, 블록되거나, 혹은 CPU를 자발적으로 양보(voluntarily yields)할 때까지 실행된다.
- 커널 데이터 구조에서의 경쟁 상태로부터 자유롭다.
- Preemptive Kernel
- 커널 모드에서 실행중인 (선점된) 프로세스를 허용한다.
- 디자인하기 어려우나 반응성이 더 좋기 때문에 유리하다.
🌱 Peterson’s Solution
임계 영역 문제를 해결하는 소프트웨어 솔루션은 다음과 같다.
- Dekker’s Algorithm(데커 알고리즘)
- 두 개의 프로세스에 대한 해결 알고리즘
- flag와 turn이라는 변수로 크리티컬 영역에 들어갈 프로세스를 결정하는 방식이다.
- Eisenberg and McGuire’s Algorithm(아이젠버그와 맥과이어 알고리즘)
- n개의 프로세스에 대한 해결 알고리즘
- 유한한 시간 내의 n - 1번의 시도 후 크리티컬 영역 진입을 보장한다.
- Bakery Algorithm(Lamport; 램포트)
- 각 프로세스에 번호를 할당하는 방식(오름차순)
- 같은 번호를 할당받았을 때 pid가 더 작은 순서로 우선순위가 부여된다.
- Peterson’s Algorithm
이 중 마지막에 언급한 피터슨 알고리즘은 가장 완벽하게 해결한 알고리즘이다. 대신 개런티(보장)가 없다.
해당 알고리즘은 두 개의 플래그를 세워 Entry Section과 Exit Section을 정의하고 Critical Section을 확실히 정해준다. 데커 알고리즘과 마찬가지로 flag와 turn 변수를 사용한다. 현대 컴퓨터는 load와 store와 같은 기계어를 이용해 연산을 수행하기 때문에 정확하다.

또한 이 알고리즘은 임계 영역 문제를 해결하기 위해 필요한 목표인 Mutual Exclusion, Progress, Bounded Waiting을 모두 만족한다.
한 프로세스가 크리티컬 영역에 들어가면 플래그를 변경하여 상태를 확실히 나타낼 수 있으며, 이를 이용해 위 세 목표 성립을 증명할 수 있다.
🌱 Hardware Support for Synchronization
하드웨어 기반의 솔루션을 적용하기 위해선 다음과 같은 기본 작업이 필요하다.
- Memory Barriers or Fences
- Hardware Instructions
- Atomic Variables
하드웨어 명령은 임계 영역 문제를 해결해주고 동기화 툴을 직접적으로 사용할 수 있으며 더욱 추상적인 메커니즘의 기초를 형성하는 데 사용할 수 있다.
하드웨어 솔루션은 대표적으로 Atomicity(원자성)한 특징이 있다.
- 원자적 동작은 Uninterruptible Unit을 의미한다.
- 특별한 하드웨어 Instruction(원자)을 제공한다.
- test and modify
- test and swap
테스트 및 수정, 그리고 테스트 및 교환은 아래 두 가지의 Atomic Instructions를 이용한다.
test_and_set()
// test_and_set() 정의
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return rv;
}
// test_and_set()을 이용한 "상호 배제" 구현
// 여기서 lock은 전역 변수이며 기본값으로 false를 가진다.
do {
while (test_and_set(&lock))
; /* do nothing */
/* critical section */
lock = false;
/* remainder section */
} while (true);
compare_and_swap()
// compare_and_swap() 정의
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
// compare_and_swap()을 이용한 "상호 배제"
// 여기서 lock은 전역 변수이며 기본값으로 0을 가진다.
while (true) {
while (compare_and_swap(&lock, 0, 1) != 0)
; /* do nothing */
/* critical section */
lock = 0;
/* remainder section */
}
compare_and_swap() 명령어는 Atomic Variable(이하 아토믹 변수)을 구성하는데 사용된다.
아토믹 연산은 Integer나 Boolean같은 기본적인 데이터 타입을 이용하며, 아토믹 변수를 사용하면 인터럽트를 무시한다. 즉, Context Switching이 안 되며 이는 곧 상호 배제를 보장한다고 볼 수 있다.
💡 아토믹 변수는
static으로 생성할 수 있다.
👻 글을 마치며
이번 시간에는 프로세스 동기화와 동기화 문제, 그리고 그에 대한 해결책에 대해 알아보았다. 내용이 너무 어려워서 혼란스럽다 😵 그래도 포스팅으로 정리하면서 나름 개념도 같이 정리되고 있는 것 같은데.. 아직까지는 마인드맵같은 이미지랄까.. 정확히 목차를 나눠서 정리하는 시간이 필요할 것 같다.
Leave a comment