[C++] 다중 포인터 vs 이차원 배열
👻 들어가기에 앞서
지난 시간에 배열을 공부하며 포인터와 배열의 차이점에 대해 잠시 알아보았다. 언뜻보면 포인터와 배열이 같은 기능을 하는 문법이라 생각되겠지만 이 둘은 엄연히 다른 존재라고도 말했었다. 이번 시간에는 다중 포인터와 이차원 배열을 비교해보며 어떻게 다른지 다시 한 번 더 정리해보고, 포인터, 참조 등을 사용할 때의 주의사항에 대해 알아보자.
👻 포인터 vs 배열
단일 포인터와 일차원 배열은 같은 기능을 한다고 했었다. 배열을 함수의 인자(매개 변수)로 넘겨줄 때는 포인터 형식으로 변환되어 넘어가는 것도 확인했었다. 그래서 배열의 이름은 배열의 시작 주소값을 가리키는 TYPE* 포인터로 변환이 가능하다는 것을 알 수 있다.
- TYPE형 1차원 배열과 TYPE*형 포인터는 완전히 호환이 된다.
int* p;
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8 };
p = arr;
cout << p[0] << endl; // 1
cout << arr[0] << endl; // 1
cout << *p << endl; // 1
cout << *arr << endl; // 1
cout << *(p + 3) << endl; // 4
cout << *(arr + 3) << endl; // 4
이러한 점만 보면 포인터와 배열이 같아보이지만 둘은 다르다. 다중 포인터와 이차원 배열을 비교해보면서 둘의 차이점을 확실히 알아보자.
🌱 다중 포인터 vs 이차원 배열
여기 이차원 배열과 이중 포인터가 있다.
int arr2[2][2] = { { 1, 2 }, { 3, 4 } };
int** pp = arr2; // 호환 불가
다중 포인터와 이차원 배열은 호환이 불가능하다. int** pp = (int**)arr2;로 형변환을 하면 가능해보이지만 예외가 발생하며 여전히 불가능하다. 애당초 타입이 맞지 않아 발생하는 문제이다. 메모리를 확인해보자.
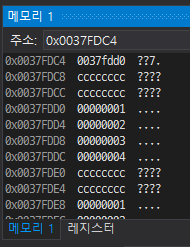
다음은 &pp의 값, 즉 pp의 주소값이다. 해당 바구니엔 0037fdd0이라는 값이 들어있고 그 주소로 넘어가면 1이 담겨있는 배열 arr을 가리키고 있다는 것을 알 수 있다.
pp는 이중 포인터이므로 주소를 타고 타고 간 곳에도 주소가 있어야 한다고 말하고 있지만, 정작 내용은 배열의 값인 1이 담겨있어 제대로 메모리를 찾아가지 못 하게 되는 것이다.
그래서 해당 코드는 주소를 타고 넘어간 곳에 값이 있다는 것을 알려줘야 하므로 다중 포인터는 사용할 수 없게 되는 것이다.
int* pp = arr2;
// 물론 배열의 형변환을 이용해 사용할 수 있다.
// 하지만 배열의 값을 일차원적으로밖에 가져오지 못한다.
// int* pp = (int*)arr2;
주소를 한 번만 타고 넘어가니 단일 포인터를 사용해야 하는데 이렇게 적으면 에러가 나는 것을 확인할 수 있다. 에러 메세지를 확인해보자.
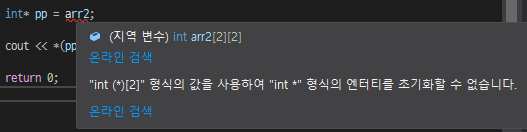
int(*pp)[2] = arr2;
해당 타입으로 변환해주니 에러가 사라졌다. 위의 코드의 뜻은 단일 포인터를 사용할 때와 같지만, 이차원 배열이므로 한 배열 안의 모든 인덱스에 접근하기 위해 배열 표시를 붙여준 것이다. 이렇게 코드를 적게되면 다음과 같이 배열에 접근이 가능하다.
cout << (*pp)[0] << endl; // 1
cout << (*pp)[1] << endl; // 2
cout << (*(pp + 1))[0] << endl; // 3
cout << (*(pp + 1))[1] << endl; // 4
cout << pp[0][0] << endl; // 1
cout << pp[0][1] << endl; // 2
cout << pp[1][0] << endl; // 3
cout << pp[1][1] << endl; // 4
하지만 이차원 배열에 대해 포인터로 접근하는 것은 잘 사용하는 부분은 아니니 참고만 해두도록 하고, 포인터에 대한 개념을 완벽히 익히고 배열과의 차이점에 대해서만 잘 알고 있으면 될 것 같다.
👻 주의사항
이제 데이터에 접근하는 방법을 아주 다양하게 배웠다. 포인터도 있고 참조도 있는데, 이제 이를 활용하면 훨씬 편리하게 개발을 할 수 있을 것 같지만 생각보다 중요하다고 손가락이 아프도록 공부해왔으니 마지막으로 사용 시에 주의해야 할 사항들을 간단하게 정리해보자.
- 함수 반환 타입에 사용하는 경우
int& TestRef() {
int a = 1;
return a;
}
int* TestPointer() {
int a = 1;
return &a;
}
굉장히 문제가 된다.
조금이라도 더 간편하고 메모리를 덜 사용하기 위해 반환값을 참조하거나 포인터로 내보내는 경우 아주 위험하다. 위처럼 함수를 작성하고 main 함수에서 TestPointer();를 사용하여 포인터의 주소값을 넘겨받았다고 가정해보자.
int main() {
int* pointer = TestPointer();
}
스택 프레임을 생각해보자.
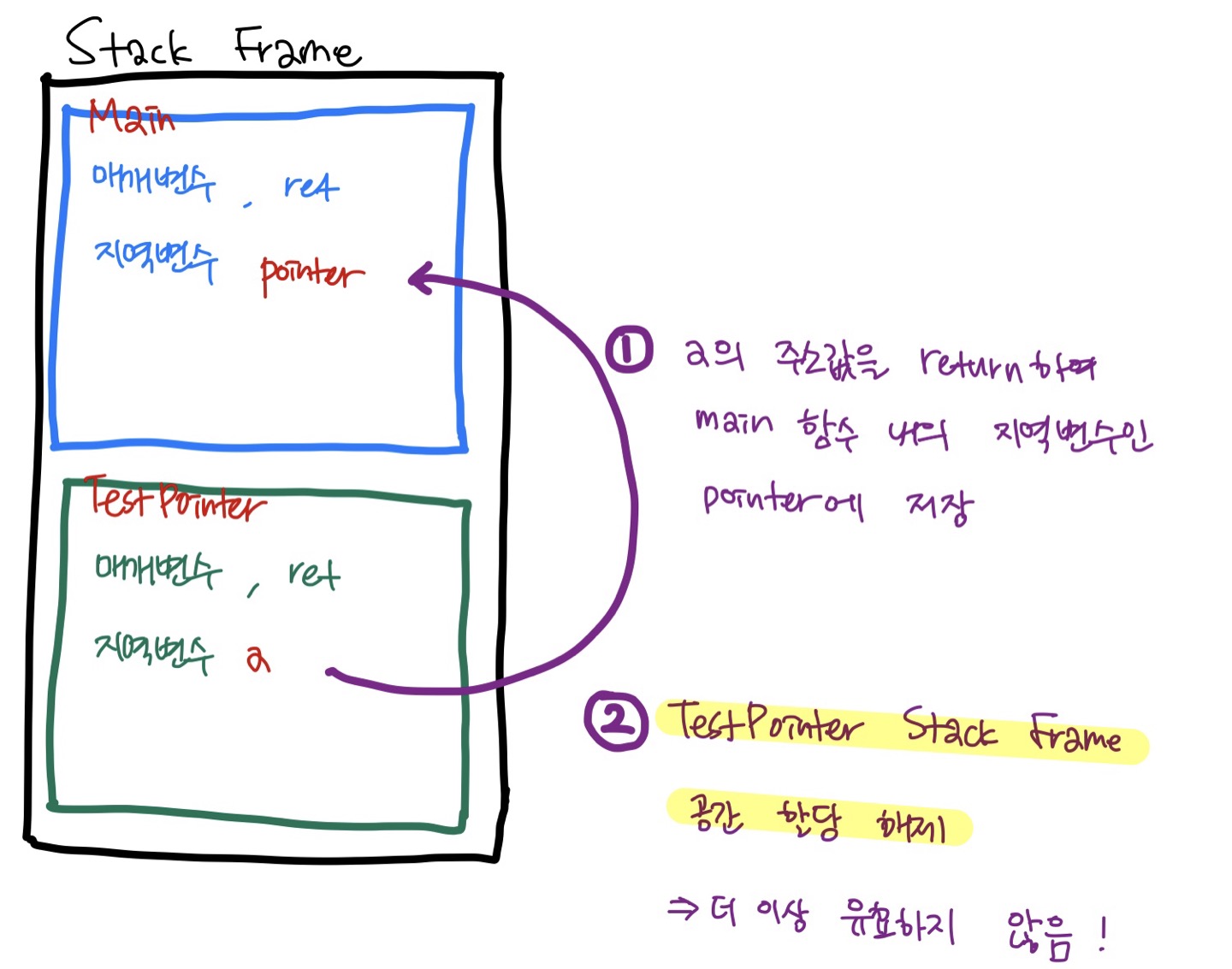
TestPointer 함수 스택 프레임이 생성되면서 해당 공간 내에 지역 변수인 a가 할당되고, 그 a의 주소를 main 함수 스택 프레임의 지역 변수로 값을 전달해주었다. 딱 봐도 하면 안 될 것 같은 방법이다.
사실 TestPointer 함수는 a의 주소값을 넘겨준 후 할 일을 다 했기 때문에 스택 프레임 할당은 해제된다. 하지만 값은 그대로 남아있기 때문에 *pointer의 값을 바꾼다 하더라도 에러는 나지 않는다. 그러나 유효 범위가 아니기 때문에 이렇게 사용되는 메모리는 옳은 값이 아님을 유추할 수 있다.
void TestWrong(int* ptr) {
int a[100] = {};
a[99] = 0xAAAAAAAA; // 디버깅 편하게 하기 위해
*ptr = 0x12341234;
}
int main() {
TestWrong(pointer);
}
다음으로 포인터를 매개 변수로 입력받아 해당 주소가 가리키는 값을 변경하는 함수가 있다고 가정해보자. 이미 이전 단계에서 pointer는 유효하지 않은 값을 가리키고 있다는 것을 알 수 있다. TestPointer의 스택 프레임이 해제되고 이어서 바로 TestWrong 함수의 새 스택 프레임이 생기게 되고, 그 안에서 포인터의 값을 변경시키는 코드는 어떻게 될까?
*ptr = 0x12341234; 부분에 브레이크 포인트를 잡고 디버깅을 실행시킨 후 메모리에 &a[99] 를 입력해 주소를 찾아가보았다.
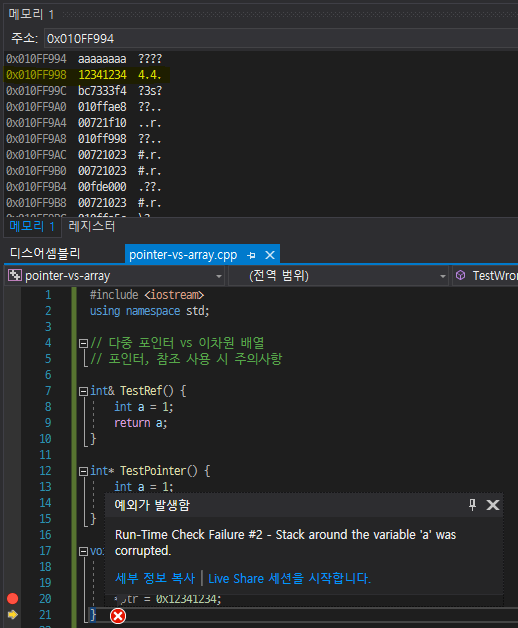
a[99]의 값이 aaaaaaaa로 잘 들어가 있는 것을 확인할 수 있고, 여기서 F10을 눌러 한 줄씩 실행시키면 바로 다음 주소에 12341234 값이 들어간 것을 알 수 있다. 그리고 한 번 더 F10을 눌러 한 줄을 실행시키면 함수를 빠져나오는 순간 예외가 발생하게된다. 참고로 이건 컴파일러가 알아서 버그를 잡아주는 부분에서 걸린 버그이고 결론은 유효 범위를 벗어난 포인터의 값을 건드려서 나는 에러이다.
해당 주소가 활성화된 스택 프레임 내에 있는지 아닌지, 값을 덮어씌우는 곳에 ebp, ret 주소같이 중요한 정보가 담겨있는지, 디버깅 모드에서 오버플로우 여부를 탐지하고 있던 장소인지 모두 중요한 포인트를 잡게 되는데 이렇게 유효하지 않은 범위에 있는 주소값을 가리키게 되면 메모리 오염이 되는 것이다. 그러니 포인터를 사용하거나 참조를 사용할 땐 항상 조심해야 한다.
👻 글을 마치며
이번 시간에는 포인터를 마무리하는 시간으로, 다중 포인터와 이차원 배열의 비교, 그리고 포인터 및 참조를 잘못 사용했을 때 나타나는 메모리 오염에 대해 알아보았다. 계속 이야기하다보니 프로그래밍 시에는 메모리 활용이 가장 중요한 것 같이 느껴졌다. 메모리의 유효 범위의 중요성이 9할은 되고, 그 다음은 자잘하게 용량을 차지하는 정도..? 라고 느껴졌다. 그래도 컴파일러가 매번 내가 짠 코드를 빌드하면서 체크를 해주니 이렇게 편하지 않을 수 없다. 하지만 오염된 메모리를 건드는 순간 에러가 날지 안날지는 모르는 일이고, 안 나면 훨씬 위험한 것이니 애초에 그럴 일이 없게끔 잘 인지하고 사용해야 할 것 같다.
Leave a comment