[ASM] 문자와 엔디언(Endian)
👻 변수 선언
지난 시간에 변수 선언과 메모리↔레지스터 사이의 데이터 이동에 대해 알아보았다.
이번 시간엔 문자 타입과 복수 선언에 대해 알아보도록 하자.
🌱 문자 타입
여기서 한 번 다뤘었던 부분이다. 변수 선언은 이전 시간에 배웠던 상수 선언과 크게 다르지 않다.
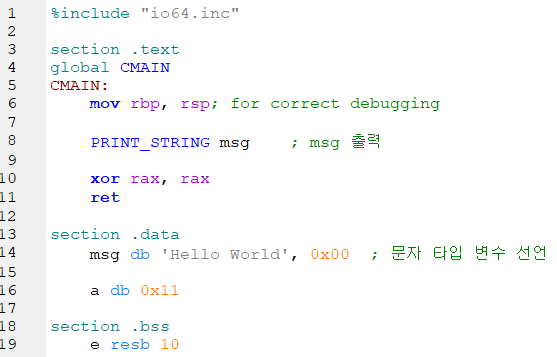
일반 상수 변수 선언과 똑같이 초기값이 정해져있는 변수이므로 data 영역에 선언을 해준다.
PRINT_STRING 은 공식적인 어셈블리 코드가 아닌, 편리한 output을 위해 SASM이 만들어놓은 매크로이다.
🌱 여러 개의 변수 세팅
변수를 선언할 때에는 여러 개를 동시에 세팅할 수 있는데 간단하게 콤마(,)로 구분하여 계속 선언해주면 된다.
section .data
a db 0x11, 0x22, 0x33, 0x44
그런데 이렇게 되면 메모리에는 어떻게 저장이 되는 지 궁금해졌다. 바로 코드를 디버깅해서 확인해보자.

a는 여전히 첫 번째 위치를 가리키고 있지만 옆 주소의 공간에 다음 데이터들이 1바이트씩 차례대로 할당받은 것을 알 수 있다.
앞서 문자 변수인 msg 선언 시
, 0x00을 붙인 것은 문자열의 끝부분을 알리기 위함이라는 것을 알 수 있다. (C 스타일의 코드임)
👻 문자 타입의 저장 방식
그렇다면 문자 타입의 변수는 메모리에 어떻게 저장되는 지 확인해보자. 다시 디버깅을 시작한 다음 메모리 탭에서 msg를 입력하여 값을 살펴보자.

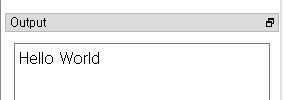
Hello World 문자 그 자체가 아닌 각 알파벳에 대응하는 아스키 코드값이 들어가있다.
문자 데이터를 저장 시 아스키 코드로 변환되어 저장되는 것을 알 수 있다.
🌱 ASCII Code
미국정보교환표준부호(American Standard Code for Information Interchange), 줄여서 ASCII는 영문 알파벳을 사용하는 대표적인 문자 인코딩 방식 이다.
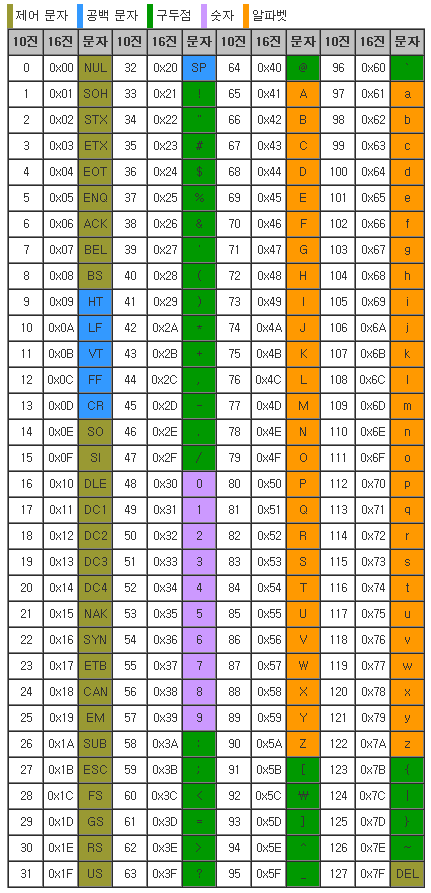
아스키 코드는 굳이 외울 필요는 없고 필요할 때마다 표를 참고해서 의미를 파악하면 된다.
위에서 msg의 메모리를 살펴봤을 때 들어가있던 값들을 각각 변환시키면 Hello World가 나오게 되는 것이다. 반대로 아스키 코드값을 변수값으로 선언한 뒤 출력을 해도 똑같은 결과값이 나올 것이다.
; 'Hello World'를 아스키 코드로 변환
msg db 0x48,0x65,0x6c,0x6c,0x6f,0x20,0x57,0x6f,0x72,0x6c,0x64,0x0
👉 결과값은 'Hello World'로 동일
동일한 데이터라고 해도 어떻게 분석하느냐에 따라 다른 의미가 부여될 수도 있다.
👻 엔디언(Endianness) 개념과 종류
엔디언(Endianness)은 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법을 뜻하며, 바이트를 배열하는 방법을 특히 바이트 순서(Byte order)라 한다.
엔디언은 보통 작은 단위가 앞에 나오는 리틀 엔디언(Little-endian)과 큰 단위가 앞에 나오는 빅 엔디언(Big-endian)으로 나눌 수 있으며, 두 경우에 속하지 않거나 둘을 모두 지원하는 것을 미들 엔디언(Middle-endian)이라 부르기도 한다.
통상적으로 많이 쓰이는 리틀 엔디언과 빅 엔디언에 대해 알아보자.
우선 data 영역에 코드를 한 줄 추가해주고 디버깅을 통해 메모리에 값이 어떻게 들어갔는 지 확인해보자.
b dd 0x12345678
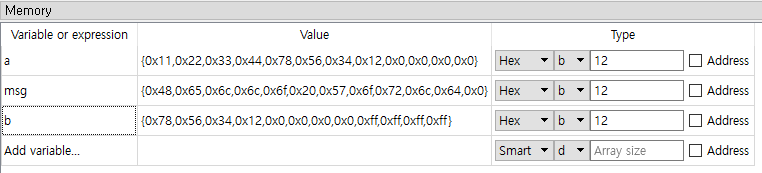
1바이트씩 끊어서 뒤집어진 채로 데이터가 저장되어있는 것을 알 수 있다.
🌱 리틀 엔디언(Little-endian)
이렇게 뒤집어져 저장되는 방식을 리틀 엔디언이라 하고 데이터를 1바이트씩 끊어 가장 최하단 바이트부터 메모리에 차례대로 저장되는 방식이라고 보면 된다.
대부분의 데스크탑 환경에서는 리틀 엔디언 방식으로 저장된다고 보면 된다. (ex. Intel, AMD, …)
b dd 0x12345678
👉 {0x78, 0x56, 0x34, 0x12, ...}
🌱 빅 엔디언(Big-endian)
반대로 원래 순서대로 저장되는 방식을 빅 엔디언이라한다. 만약에 지금 내 실습 환경이 빅 엔디언 방식을 사용했다면 메모리에 저장된 데이터의 순서는 다음과 같았을 것이다.
b dd 0x12345678
👉 {0x12, 0x34, 0x56, 0x78, ...}
🌱 리틀 엔디언 VS 빅 엔디언
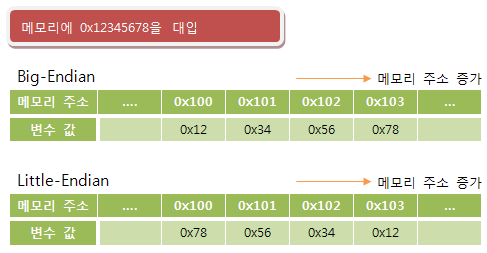
해당 저장 방식은 개발 환경마다 다르다. 1인 개발 프로젝트를 진행하는 경우에는 굳이 신경을 쓰지 않아도 되지만, 여러사람의 협업을 통해 진행되는 프로젝트의 경우는 네트워크 전송 시 서버 환경에 따라 데이터 분석 방식이 달라질 수 있으니 주의해야한다.
그렇다면 왜 굳이 불편하게 리틀 엔디언 방식을 사용할까?
👉 장단점이 교차한다.
- 리틀 엔디언 : 캐스팅에 유리하다.
💡 캐스팅이란?
보통 형변환을 캐스팅이라 하는데 여기에서는 길이 변경을 뜻하는 듯하다. 여기서는 최하단 1바이트를 남기고 나머지를 날리고 싶을 때를 예시로 들었다. - 빅 엔디언 : 숫자 비교에 유리하다.
대소관계 비교 시 앞 메모리 1바이트만 추출하면 비교가 쉽다.
👻 글을 마치며
오늘은 문자 변수 선언, 문자 저장 방식, 그리고 저장 순서인 엔디언에 대해 배웠다. 계속 공부를 하다보니 같은 기능이지만 여러가지 방식을 배우는 패턴이 많은 것 같은 느낌을 받았는데, 컴퓨터가 점차 진보되면서 부가적으로 생겨났다고 생각하니 신기한 것 같다. 각자 장단점이 교차되고, 필요에 따라 원하는 방식을 사용할 수 있으며 반대로 알고있어야만 해결할 수 있는 문제들도 있을거라 생각하면 확실하게 알아야겠다는 생각을 했다. 앞으로 갈 길이 구만리구만 😂
Leave a comment