[ASM] 배열과 주소
👻 배열
배열은 동일한 타입의 데이터 묶음을 의미한다.
- 배열을 구성하는 각 값을 배열 요소(element)라고 한다.
- 배열의 위치를 가리키는 숫자를 인덱스(index)라고 한다.
배열의 선언은 간단하다.
이전 시간에 변수를 선언했던 것처럼 똑같이 선언해주면 되는데 값을 여러개 붙이면 배열로 선언이 된다.
section .data
a db 1, 2, 3, 4, 5, 6 ; 5 * 1 = 5바이트 배열
b times 5 dw 1 ; 5 * 2 = 10바이트 배열
section .bss
num resb 10 ; 10개짜리 num공간. 초기값은 모두 0
.data 영역에서는 여러개를 지정해주면 배열로 선언이 되고, .bss 영역에서 개수를 2개 이상으로 늘려주면 모두 0인 배열이 생성된다.
🌱 연습 문제
a 배열의 모든 데이터 출력해보기
xor ecx, ecx ; counter
LABEL_PRINT_A:
PRINT_HEX 1, [a+ecx]
NEWLINE
inc ecx
cmp ecx, 5
jne LABEL_PRINT_A
xor rax, rax
ret
section .data
a db 0x01, 0x02, 0x03, 0x04, 0x05
b 배열의 모든 데이터 출력해보기
xor ecx, ecx ; counter
LABEL_PRINT_B:
PRINT_HEX 2, [b+ecx*2]
NEWLINE
inc ecx
cmp ecx, 5
jne LABEL_PRINT_B
xor rax, rax
ret
section .data
b times 5 dw 1
위의 두 코드처럼 배열의 모든 값을 출력하고 싶으면 이전에 배웠던 반복문을 사용하면 된다.
🌱 배열의 주소
방금 다뤘던 연습 문제 중 b 배열의 모든 데이터를 출력하는 부분에서 배열의 주소가 a 배열 출력 때와 다르다는 것을 확인할 수 있다. a 배열의 모든 데이터를 출력할 때처럼 작성하면 결과값은 1이 다섯 개가 출력되는 게 아닌 1, 100, 1, 100, 1이 출력된다.
이전에 환경에 따라 데이터 저장 방식이 리틀 엔디언과 빅 엔디언으로 나눠진다고 했었다.
👉 복습하러 가기 👈
디버깅을 통해 메모리를 확인해보면 b 배열의 데이터는 아래와 같이 리틀 엔디언방식으로 저장되어있다.
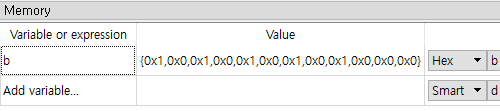
각 값은 2바이트를 1바이트 씩 나눠서 저장되므로 각 숫자의 앞에 0이 붙어있다고 보면 된다.
0x0은0x00,0x1은0x01이다.
그렇다는 뜻은 ecx에 해당하는 위치에서 2바이트씩 데이터를 가져와서 출력하겠다는 의미인데, 첫 번째는 0x1, 0x0을 가져온 후 위치를 바꿔 0x0001로 출력을 하게된다. 해당 값은 1이 맞다.
두 번째부터 문제가 된다. 인덱스는 1씩 증가하게 되는데 그렇게되면 두 번째에 저장되어있는 0x0을 가리키게 되고, 거기서부터 2바이트를 가져오면 0x0, 0x1이 되고 순서를 뒤집어서 해석해보면 0x0100 즉 100이 출력되는 것이다.
고로 배열의 주소는 [시작 주소 + 인덱스 * 크기]라고 할 수 있다. a 배열의 경우 크기가 1바이트라
[* 크기]가 생략된 것이라 볼 수 있다.
어셈블리 외의 컴파일러는 자동으로 크기만큼 인덱스를 증가시켜줘서 고려하지 않아도 되지만, 어셈블리어에서는 이렇게 인덱스까지 우리가 직접 제어해줘야한다.
👻 글을 마치며
이번 시간에는 배열에 대해 알아보았다. 개인적으로 좋아하는 타입인데 어셈블리에서는 뭐든 직접 건드려야하니 복잡한 것 같다. 배열은 주소와 값이 쌍으로 묶여져 있는 데이터의 연속이라 개념 정리를 확실히 하지 않으면 갑자기 헷갈려서 이해하기 어려워질 수 있으니 꾸준한 복습이 필요할 것 같다.
Leave a comment