[Algorithm] 트리(Tree)와 힙(Heap)
👻 트리(Tree)
트리(Tree)란 계층적 구조를 가지는 데이터를 표현하기 위한 자료 구조이다. 그래프와 비슷하게 노드와 간선을 가지지만 계층적 구조를 가지는 것이 큰 차이이다.
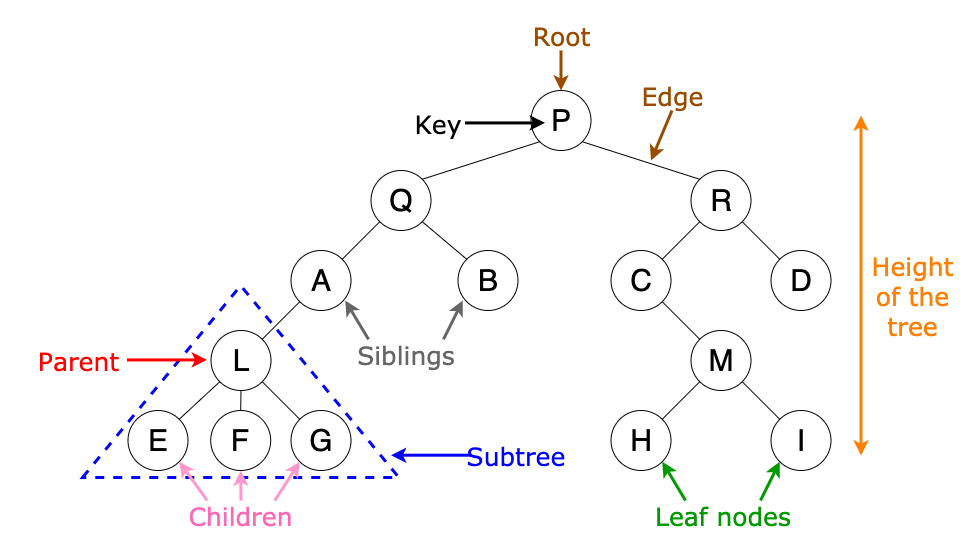
용어 정리
- 부모(Parent) 노드 : 노드를 가지고 있는 노드
- 자식(Child) 노드 : 다른 노드가 가지고 있는 노드
- 형제(Sibling) 노드 : 같은 부모 노드를 가지고 있는 노드
- 선조(Ancestor) : 기준 노드로부터 n단계 위에 존재하는 노드
- 자손(Descendant) : 기준 노드로부터 n단계 밑에 존재하는 노드
- 루트(Root) : 최상위 노드
- 잎(Leaf) : 최하위 노드
- 깊이(Depth) : 최상위 노드는 0번이고 밑으로 내려갈수록 1씩 증가(깊어짐)
- 높이(Height) : 트리의 층수. 최상위 노드가 1층부터 시작.
- 트리의 재귀적 속성 및 서브트리(Subtree) : 트리의 부분도 동일한 트리 구조를 띄는 속성
🌱 구현 연습
- 트리 만들기
코드로 트리를 만들 때에는 노드를 이용한다.
using NodeRef = shared_ptr<struct Node>;
struct Node
{
Node() {}
Node(const string& data) : data(data) {}
string data;
vector<NodeRef> children;
};
그리고 싶은 트리 구조에 따라 자식 노드를 children에 추가하면 쉽게 완성할 수 있다.
- 트리 출력하기
void PrintTree(NodeRef root, int depth)
{
for (int i = 0; i < depth; i++)
cout << "-";
cout << root->data << endl;
for (NodeRef& child : root->children)
PrintTree(child, depth + 1);
}
재귀적 속성을 이용하여 모든 노드에 순차적으로 접근할 수 있으며 깊이를 알고싶다면 깊이값을 사용하여 구할 수 있다.
- 트리 높이 구하기
// 깊이(Depth) : 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수 (aka. 몇 층?)
// 높이(Height) : 가장 깊숙히 있는 노드의 깊이 (max(depth))
int GetHeight(NodeRef root)
{
int height = 1;
for (NodeRef& child : root->children)
height = max(height, GetHeight(child) + 1);
return height;
}
높이를 구할 때에도 구조 출력과 동일하게 재귀적 특성을 이용한다. 단, 깊이와는 다르게 루트 노드가 1부터 시작하고 가장 깊은(가장 숫자가 큰) 노드에 도달하면 해당 높이를 트리의 최종 높이로 반환한다.
- 결과

👻 힙(Heap) 트리
힙(Heap) 트리는 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료 구조이다. 이진 트리는 각 노드가 최대 두 개의 자식 노드를 가지는 트리이며 완전 이진 트리는 모든 노드가 두 개의 자식 노드를 가지는 트리를 의미한다.
💡 이진 트리는 자식 노드가 0~2개, 완전 이진 트리는 마지막 레벨 노드를 제외한 모든 노드가 자식 노드를 반드시 2개를 가지는 트리이다. (리프 노드는 반드시 왼쪽부터 채워져 있어야한다.)
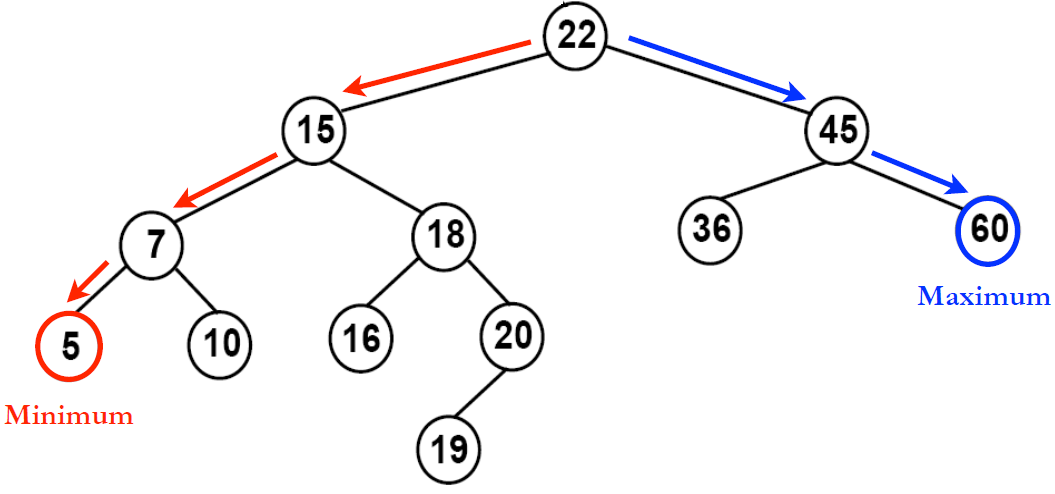
이진 탐색 트리(Binary Search Tree)의 특징
- 왼쪽을 타고 가면 현재 값보다 작다.
- 오른쪽을 타고 가면 현재 값보다 크다.
이진 탐색 트리의 문제점
- 그냥 무식하게 추가하면 한 쪽으로 기울어져서 균형이 깨질 수 있다.
- 트리 재배치를 통해 균형을 유지하는 것이 과제이다.(AVL, Red-Black)
🌱 힙 트리의 특징
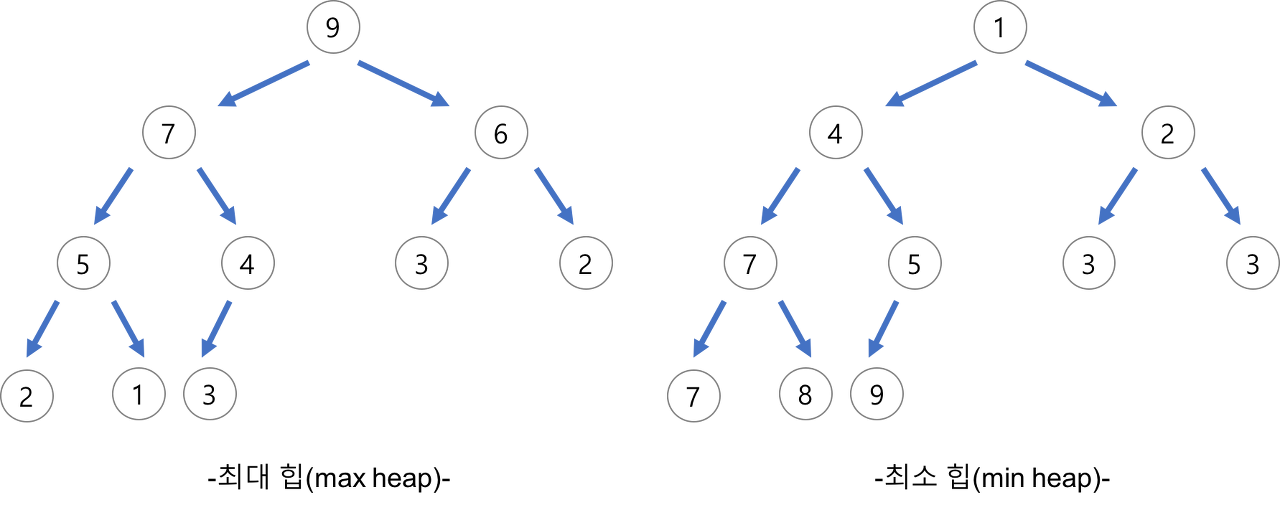
힙 트리도 이진 트리에 속하지만 이진 탐색 트리와는 조금 다른 특징을 가진다.
- [1법칙] : 부모 노드가 가진 값은 항상 자식 노드가 가진 값보다 크다.
- [2법칙] : 노드 개수를 알면 트리 구조는 무조건 확정할 수 있다.
- 마지막 노드를 제외한 모든 노드는 2개의 자식 노드를 가지는 완전 이진 트리 구조이다.
- 마지막 노드가 있다면 항상 왼쪽부터 순차적으로 채워져야 한다.
- 배열을 이용해서 힙 구조를 바로 표현할 수 있다. (
vector<int> heap(5);)i번 노드의 왼쪽 자식은[(2 * i) + 1]번i번 노드의 오른쪽 자식은[(2 * i) + 2]번i번 노드의 부모는[(i - 1) / 2]번
💡 힙 트리에서는 중복된 값을 허용한다. (이진 탐색 트리에서는 중복된 값을 허용하지 않는다.)
👻 우선순위 큐
우선순위 큐(Priority Queue) 는 힙 트리 구조를 가지는 큐이다. 일반적인 큐와 다르게 우선순위를 지정하여 알맞은 조건에따라 대기열을 재배치하고 값을 반환한다.
int main()
{
// priority_queue<int, vector<int>, greater<int>> pq; // 최소 힙(min heap)
priority_queue<int> pq; // 최대 힙(max heap)
pq.push(100);
pq.push(300);
pq.push(200);
pq.push(500);
pq.push(400);
while (!pq.empty())
{
int value = pq.top();
pq.pop();
cout << value << endl;
}
}
위와 같은 코드가 있다고 했을 때, 결과값은 선입선출 순이 아닌 내림차순으로 반환된다.
💡 기본적으로 힙 트리 구조는 최대 힙(Max Heap) 트리 구조이다. (내림차순)
오름차순으로 반환하고 싶으면 세 번째 인자를 설정해주면 된다.
priority_queuetemplate <class _Ty, class _Container = vector<_Ty>, class _Pr = less<typename _Container::value_type>> class priority_queue { public: ... };
🌱 구현 연습
template<typename T, typename Container = vector<T>, typename Predicate = less<T>>
class PriorityQueue
{
public:
void push(const T& data)
{
// 우선 힙 구조부터 맞춰주기
_heap.push_back(data);
// 대소 비교하며 정리하기
int now = static_cast<int>(_heap.size()) - 1; // 방금 넣은 데이터의 인덱스
// 루트 노드까지 반복
while (now > 0)
{
// 부모 노드와 비교해서 더 작으면 패배
int parent = (now - 1) / 2;
if (_predicate(_heap[now], _heap[parent]))
break;
// 데이터 교체
::swap(_heap[now], _heap[parent]);
now = parent;
}
}
void pop()
{
// 최상위 노드 제거 + 최하위 노드를 최상위로 올리기
_heap[0] = _heap.back();
_heap.pop_back();
// 최상위 노드부터 시작
int now = 0;
while (true)
{
int left = (2 * now) + 1;
int right = (2 * now) + 2;
// 리프에 도달한 경우
if (left >= _heap.size())
break;
int child = now;
// 왼쪽과 비교
if (_predicate(_heap[child], _heap[left]))
child = left;
// 둘 중 승자를 오른쪽과 비교
if (right < _heap.size() && _predicate(_heap[child], _heap[right]))
child = right;
// 왼쪽/오른쪽 둘 다 현재 값보다 작으면 종료
if (child == now)
break;
// 데이터 교체
::swap(_heap[now], _heap[child]);
now = child;
}
}
T& top()
{
return _heap[0];
}
bool empty()
{
return _heap.empty();
}
private:
Container _heap = {};
Predicate _predicate = {};
};
💡 우선순위 큐의 시간 복잡도는
O(log N)이다.
👻 글을 마치며
이번 시간에는 트리의 기초와 힙 이론, 그리고 우선순위 큐 구현을 연습해보았다. 이진 트리를 공부하면서 완전 이진 트리의 특징에 대해 완벽히 알 수 있었고 우선순위 큐가 어떤 식으로 데이터를 탐색하는 지 알 수 있었다. 아직 구현을 하려면 어디서부터 시작해야할지 감이 안 잡히지만 계속 하다보면 나아지지 않을까 싶다. ☺☺☺
Leave a comment