[Algorithm] 해시 테이블(Hash Table)
👻 해시 테이블
해시 테이블(Hash Table)이란 Key와 Value로 이루어진 자료 구조 중의 하나이다. 키와 밸류를 매핑하여 키 값 만으로 데이터를 빠르게 추가, 탐색, 삭제할 수 있다. 앞서 보았던 이진 탐색 트리(Binary Search Tree)가 O(log N)의 시간 복잡도를 가지는데, 해시 테이블은 키 값만 알면 데이터를 바로 찾을 수 있기 때문에 O(1)의 시간 복잡도를 가진다. 대신에 메모리 소모는 다른 자료 구조보다 훨씬 많다.
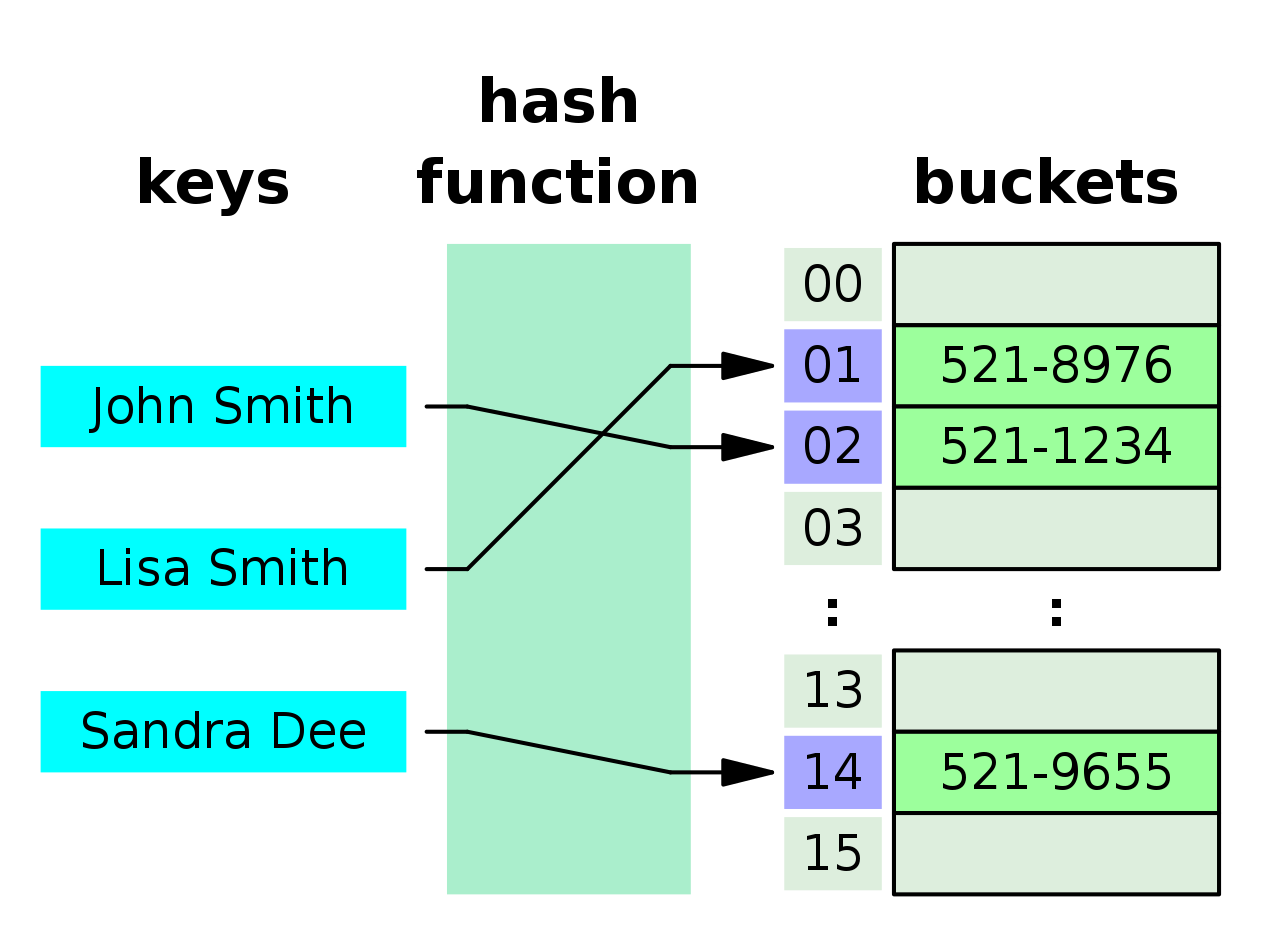
Hash Function을 이용하여 나온 키의 해시값을 버킷의 인덱스(Index)와 매핑한다. 데이터는 버킷(Bucket)이라는 이름의 테이블(배열)에 저장된다.
💡 키의 해시값을 사용하는 이유?
우선, 키 값의 원본 자체를 사용한다고 가정하면 탐색 시 모든 키 값을 탐색해야 하기 때문에 시간 복잡도는O(N)이 된다. 하지만 해시 함수를 이용하면 키 값에 해당하는 해시값만 계산하여 데이터를 바로 찾을 수 있기 때문에 속도 측면에서 굉장히 빨라지게 된다. 또한 키 값의 크기가 아무리 커져도 해시 함수를 거치면 일정한 길이 이하로만 결과가 도출되기 때문에 사이즈 관리에 훨씬 효율적이라고 볼 수 있다.
👻 Hash Collision
이렇게 키 값을 해싱하여 나온 값들을 배열의 인덱스로 사용하게 되는데, 그러다보면 키의 해시값이 겹치는, 즉 충돌하는 상황이 발생할 수 있는 가능성도 존재한다. 이렇게 키의 해시값이 충돌할 때 해결할 수 있는 방법에는 오픈 어드레싱(Open Addressing)과 체이닝(Chaining)이 존재한다.
💡 고로 해시 함수(Hash Function)를 설계할 때 효율적으로 잘 설계해야 한다.
🌱 Open Addressing
해당 기법은 충돌이 발생한 자리를 대신하여 다른 빈자리를 찾아나서는 기법이다. 대표적으로 선형 조사법(Linear Probing)과 이차 조사법 (Quadratic Probing)이 있다.
- 선형 조사법(Linear Probing)
선형 조사법은 해시값 충돌시 바로 다음 인덱스 값을 확인하여 비어있으면 데이터를 추가, 비어있지 않으면 또다시 인덱스 값을 증가시켜 확인하여 데이터를 추가하는 방법이다. 인덱스의 증가값이 일정하다.
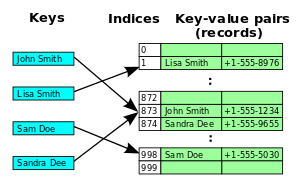
비어있는 자리를 찾을 때까지 버킷을 순회한다.
// 충돌할 때마다
hash(key) + 1 👉 hash(key) + 2 👉 ...
- 이차 조사법(Quadratic Probing)
이차 조사법은 해시값이 충돌할 때마다 인덱스의 증가값을 제곱하여 탐색하는 조사법이다. 첫 충돌시 1의 제곱만큼 인덱스 증가, 두 번째 충돌시 2의 제곱만큼 인덱스 증가하는 식으로 인덱스를 증가시킨다.
// 충돌할 때마다
hash(key) + 1² 👉 hash(key) + 2² 👉 ...
🌱 Chaining
해당 기법은 말 그대로 충돌시 기존의 데이터의 다음으로 추가할 데이터를 연결시키는 기법이다. 키의 해시값이 겹칠 경우를 대비하여 테이블 구조를 이차 배열로 만들게 되면 키의 해시값이 충돌하여도 데이터를 추가하는 덴 문제가 없을 것이다. 다만, 이런식의 자료 구조는 O(1)의 시간 복잡도를 보장할 수 없고 해당 해시값과 연결된 모든 리스트를 탐색해야 하게 될 것이다.

void TestHashTableChaining()
{
struct User
{
int userId = 0; // 1 ~ int32_max
string username;
};
vector<vector<User>> users;
users.resize(1000);
const int userId = 123456789;
int key = (userId % 1000); // hash < 고유번호
// 123456789번 유저 정보 세팅
users[key].push_back(User{ userId, "Dandi" });
// 123456789번 유저 이름은?
vector<User>& bucket = users[key];
for (User& user : bucket)
{
if (user.userId == userId)
{
string name = user.username;
cout << name << endl;
}
}
}
👻 Map VS Hash Map
맵(Map)은 레드 블랙 트리(Red-Black Tree)의 구조를 가지는 컨테이너이다. 그렇기 때문에 데이터의 추가, 탐색, 삭제가 트리의 높이인 O(log N)만큼의 시간 복잡도를 가진다.
해시 맵(Hash Map)은 해시 테이블(Hash Table)의 자료 구조를 가지는 컨테이너이다. 해당 자료 구조는 앞서 공부했던 것처럼 데이터의 추가, 탐색, 삭제가 O(1)의 시간 복잡도를 가진다.
결론적으로 맵과 해시 맵은 전혀 다른 구조로 되어있기 때문에 같은 맵 형식의 컨테이너일지라도 데이터의 추가, 탐색, 삭제에서 시간 복잡도의 차이가 크다는 것을 알 수 있다.
💡 C#의
Dictionary와 C++의Hash Map(Unordered Map)이 동일한 구조이다.
👻 글을 마치며
이번 시간에는 해시 테이블에 대해 알아보았다. 항상 맵, 해시 맵, 해시 테이블 등 다양하지만 비슷한 용어들이 많이 나와서 볼 때마다 헷갈렸었는데 이번 시간에 확실한 차이점을 알 수 있게 되었다. 더불어 해시의 의미와 테이블의 의미도 정확하게 알 수 있었다.
Leave a comment